
Авторы оригинальной публикации: Калев Литару (Kalev Leetaru) и Фелипе Хоффа (Felipe Hoffa)
Теперь мы можем анализировать, визуализировать и даже прогнозировать человеческое общество с помощью мировых новостей.
Целью проекта GDELT, поддерживаемого подразделением Google Ideas, является создание открытого, обновляемого в режиме реального времени каталога мировых новостей и предоставление доступа к этому каталогу для всех желающих. Архив проекта GDELT находится в ряду крупнейших открытых баз данных, посвященных мировому сообществу. Сложность, высокие темпы роста объема данных и аналитическая нагрузка ставят уникальные задачи в плане представления и доступности данных. Разнообразие пользователей и областей применения GDELT приводит к большому разнообразию шаблонов доступа: запросы могут обрабатывать множество столбцов в одном анализе, в результате чего использование традиционной индексированной базы данных становится неэффективным.
В результате постоянного увеличения массива тем и эмоций, вносимых каждой статьей, фреймворк GDELT должен обладать возможностью эффективно хранить и обеспечивать доступ к миллионам измерений на строку. Кроме того, все большее количество запросов направлено на анализ структур на макроуровне, для чего требуется обработка всего архива в целом. Таким образом, учитывая, что для обслуживания даже обычных запросов может потребоваться обработка терабайтов данных с помощью сложных алгоритмов, становится очевидной необходимость применения внутренней обработки (in-database execution).
Являясь открытым проектом, GDELT стремится обеспечить постоянный свободный доступ к своим данным для всех желающих. Однако, принимая во внимание внушительный объем и специфику данных, реализовать это не так просто. К счастью, существует платформа Google BigQuery, которая существенно облегчает для пользователей доступ к данным GDELT. В этой статье мы рассмотрим совместное использование GDELT и BigQuery для анализа мировых новостей в режиме реального времени.
Что такое проект GDELT?
Проект GDELT использует огромный каталог мировых новостных ресурсов, созданный в сотрудничестве с партнерами по всему миру, для осуществления мониторинга в реальном времени каждого доступного печатного, вещательного и онлайн новостного репортажа, выпущенного где-либо в мире, уделяя особое внимание региональным новостям на региональных зыках. Каждая статья сначала переводится на английский язык с помощью машинного переводчика (небольшая часть материалов переводится человеком), а затем обрабатывается набором алгоритмов. Применяемые алгоритмы способны идентифицировать сотни категорий событий (от протестов до призывов к миру), тысячи эмоций (от тревоги до воодушевления), миллионы тем (от прав женщин до обеспечения доступа к питьевой воде), а также местоположения, людей, организации и другие индикаторы.
Эти систематизированные метаданные (а не сам исходный текст статей) затем публикуются в форме свободно доступного потока данных, обновляющегося каждые 15 минут и представляющего собой многоязычный аннотированный каталог мировых новостей. Кроме того, база данных содержит обработанные таким же образом различные исторические архивы: архив, охватывающий 70 лет и содержащий 21 миллиард слов из академической литературы, включая материалы JSTOR, DTIC и Internet Archive; отчеты о правах человека за 50 лет; полмиллиона часов американских телевизионных новостей; собрание книг за 200 лет.
Что такое Google BigQuery?
Google BigQuery – это облачная платформа, предназначенная для анализа огромных база данных, таких как GDELT. BigQuery использует инфраструктуру Google для обслуживания интерактивных SQL-запросов к наборам данных, имеющим объем порядка нескольких петабайтов и содержащим десятки триллионов строк. Запросы передаются посредством REST API и выражаются в виде стандартного SQL, а также могут быть расширены с помощью определяемых пользователем JavaScript-функций для реализации сложных запросов. Каждый день пользователи загружают в BigQuery сотни терабайтов новых данных (как пакетных, так и потоковых), которые сразу же становятся доступны для запросов. Для обработки одного запроса могут быть выделены тысячи процессоров, как следствие, пользователь получает быстрый результат без необходимости индексирования или секционирования данных.
Как Google BigQuery помогает GDELT справляться с большими данными?
В виду невероятного объема и разнообразия наборов данных GDELT, задача обеспечения доступа к данным становится нетривиальной. Каким образом лучше всего реализовать доступ к базе данных, содержащей триллионы строк, в которой могут быть как традиционные таблицы содержащие, например, 310 миллионов строк и 59 столбцов, так и быстро изменяющиеся таблицы, содержащие миллионы измерений на строку и сотни миллионов строк, притом, что объем этих данных постоянно возрастает в реальном времени? Хотя все данные доступны для загрузки в виде CSV-файлов, немногие пользователи располагают необходимым дисковым пространством и вычислительной мощностью, чтобы загружать, а затем эффективно запрашивать и анализировать терабайты данных. Здесь в игру вступает платформа BigQuery, идеально подходящая для совместного применения с GDELT.
Следующие свойства BigQuery позволяют пользователям эффективно взаимодействовать с наборами данных GDELT:
-
Масштабируемость и гибкость. Наборы данных GDELT совокупно содержат десятки триллионов строк, представленных в различных форматах. Некоторые потоки данных, например, каталоги событий, таких как протесты или мирные демонстрации, имеют хорошо структурированные схемы, адаптированные для применения совместно с реляционными СУБД и оптимизированные в течение десятилетий использования. Другие потоки, такие как каталоги тем и эмоций, представляют собой фундаментально новые виды метаданных. Они созданы для использования в очень малых масштабах и еще не имеют устоявшихся форматов представления. Кроме того, количество измерений постоянно увеличивается, что требует применения гибкой схемы, способной к постоянному расширению. Каждое добавленное измерение должно кодировать некоторую числовую информацию, например, степень близости к другой информации или интенсивность. Для этого требуется гибкий формат данных, поддерживающий сложную вложенность, числовые величины и постоянное расширение. Все это обеспечивает BigQuery.
-
Постоянное добавление новых столбцов. Один из наборов данных GDELT содержит информацию о наличии, контексте и интенсивности тем и эмоций новостных сообщений. Перечень тем и эмоций постоянно растет с течением времени, что требует возможности запрашивать и анализировать миллионы измерений на строку, каждое из которых хранит числовое значение оценки. BigQuery предоставляет широкую поддержку регулярных выражений, которые GDELT использует для хранения данных во вложенных форматах и извлечения требуемых значений во время выполнения запроса.
-
Объединение исторических данных и данных реального времени. Структуры, возникающие в реальном времени в процессе поступления новых данных в GDELT, могут рассматриваться в контексте исторических архивов, что позволяет определить их важность, актуальность и лежащие в их основе движущие силы. Новые данные, поступающие в режиме реального времени, должны быть доступны как можно быстрее, чтобы обеспечить возможность анализа текущих событий, поэтому необходима среда, поддерживающая унифицированные запросы, как в отношении данных реального времени, так и в отношении исторических данных. BigQuery реализует эту концепцию с помощью потоковой вставки (streaming insert).
-
Специализированный безиндексный поиск (index-free search) по многим столбцам. Один из наборов данных GDELT представляет собой архив мировых событий за 37 лет, содержащий 310 миллионов строк и 59 столбцов. Как правило, запросы обращаются к некоторой комбинации столбцов, при этом каждый запрос интересует своя комбинация. Какой-либо один столбец или какое-либо подмножество столбцов не могут обеспечить существенную редукцию, в связи с чем невозможно использовать традиционную индексированную реляционную модель. Вместо этого необходима модель на основе безиндексного поиска, которую реализует BigQuery.
-
Публичный доступ. Все потоки данных GDELT находятся в свободном доступе. Это означает, что для GDELT необходима платформа, позволяющая отделить ресурсы, связанные с размещением и управлением данными, от ресурсов, связанных с обслуживанием запросов. BigQuery обеспечивает публичный доступ к данным.
-
Поддержка сложных вычислений. Запросы GDELT обычно задействуют сложную логику, например, сопоставление тем и местоположений в некотором документе, что потенциально требует обработки терабайтов данных. Следовательно, для GDELT необходима возможность выполнять сложные алгоритмы полностью внутри самой платформы. Это реализуется с помощью определяемых пользователем функций BigQuery.
-
Внутренняя обработка полного объема данных. Для некоторых видов анализа необходима возможность эффективно обрабатывать всю базу данных в целом. Например, для исследования структур и циклов истории на основе мировых новостей необходима возможность выполнять поиск взаимосвязей по всей базе данных в целом с помощью движущегося окна. Для этого, в свою очередь, требуется прозрачное масштабирование вычислений и перемещений данных. Огромное количество процессоров, необходимое для данного вида анализа, может обеспечить лишь облачная среда, такая как BigQuery.
BigQuery и GDELT в действии
BigQuery позволяет исследовать огромные архивы GDELT почти в реальном времени, интерактивно выполняя запросы, анализ и визуализацию. Часто BigQuery используется для анализа тенденций протестов или конфликтов в данной стране и позволяет поместить текущие события в исторический контекст. Например, на рисунке ниже представлена диаграмма нестабильности в Чили начиная с 1979 года. Особо выделяется восстание против режима Пиночета с 1983 по 1988 и его арест десятилетие спустя в октябре 1998. После этого в стране наблюдается относительная стабильность. Аналогичный подход недавно был использован для сравнения тенденций, свойственных протестам в Европейском союзе, имевшим место за последние 40 лет. Данный тип анализа является очень мощным инструментом, потому что позволяет охватить миллионы мировых событий, произошедших в течение десятилетий, и быстро сгенерировать хронологическую количественную характеристику нестабильности в той или иной стране, которая с большой точность показывает периоды нарастаний и спадов протестной активности.
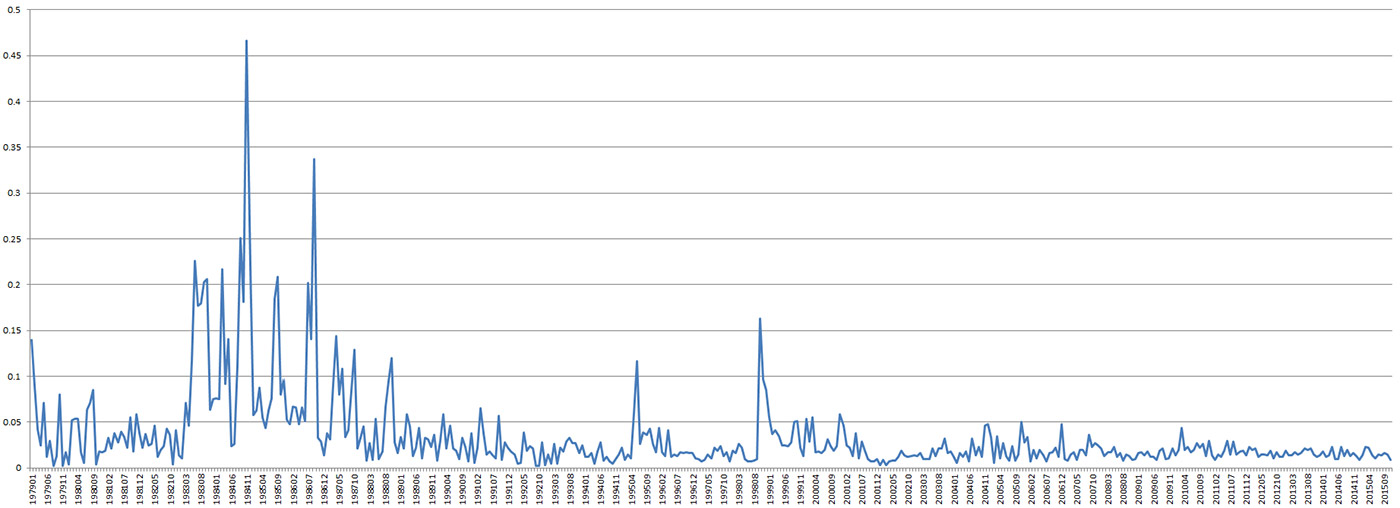
Рисунок 1. Хронология нестабильности в Чили глазами GDELT и BigQuery (ось Y представляет «интенсивность» нестабильности).
Другой набор данных GDELT содержит имена людей, названия организаций, местоположения, темы и эмоции, найденные в новостных статьях. Благодаря BigQuery, с помощью всего лишь одной строки SQL-кода было просканировано 150 миллионов новостных статей, и сформирован список из 1500 пар имен, чаще всего упоминавшихся совместно в новостях, касающихся референдума по финансовой политике в Греции. Эта операция была выполнена за несколько секунд. На выходе был создан CSV-файл, предназначенный для визуализации с помощью Gephi. Полученная в результате сетевая диаграмма представлена ниже. Данный тип диаграмм позволяет пользователю быстро выяснить, как та или иная тема освещалась в новостях, какие личности являлись центральными фигурами, и как они были связаны друг с другом. В данном случае решающую роль сыграли следующие европейские лидеры: Ангела Меркель и Вольфганг Шойбле от Германии, Жан-Клод Юнкер от Люксембурга и Франсуа Олланд от Франции.

Рисунок 2. Сетевая диаграмма персон, чаще всего упоминавшихся совместно в новостных репортажах в Греции в период с 1 по 15 июля 2015 года.
Еще одним примером использования BigQuery совместно с GDELT является отображение на карте местоположений, упоминаемых в контексте некоторой темы. BigQuery поддерживает определяемые пользователем функции, что позволяет создавать JavaScript-приложения любой сложности. Например, можно реализовать вложенные циклы и сложную фильтрацию, которая ассоциирует каждую тему с ее ближайшим местоположением в документе. Подобные JavaScript-приложения выполняются, как часть запроса, что позволяет выполнять всю аналитику полностью в BigQuery. На рисунке ниже с помощью CartoDB визуализированы все местоположения, упоминаемые в контексте преступлений против дикой природы в период с февраля по июнь 2015 года. Эта карта была создана, чтобы показать, насколько широко распространены подобные преступления. Другие визуализации, созданные с помощью GDELT и BigQuery, позволяют анализировать географию таких тем, как противотанковое оружие, изменение климата, долговой кризис в Греции, Исламское государство, а также местоположения, упоминаемые в книгах за 200 лет.
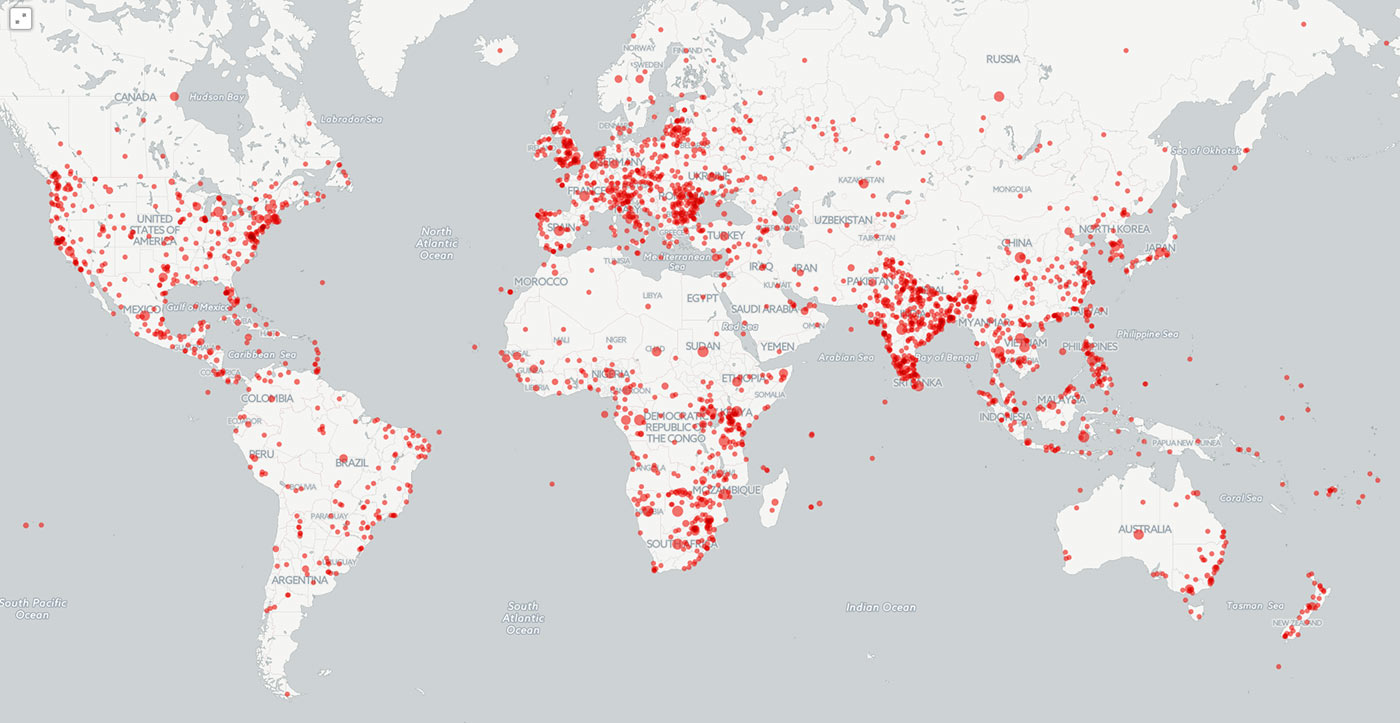
Рисунок 3. Местоположения, упомянутые в контексте преступлений против дикой природы в мировых новостях в период с февраля по июнь 2015 года.
Сотрудники исследовательского подразделения банка BBVA выполнили ряд исследований и визуализаций с помощью GDELT и BigQuery. Среди них карта миграционного кризиса в Европе, представленная ниже, а также моделирование динамики социальных волнений. На карте миграционного кризиса показаны местоположения притока (оранжевый) и оттока (красный) беженцев в Европе и Северной Африке в течение первых шести месяцев 2015 года. Подобные карты, визуализирующие тенденции на основе миллионов новостных сообщений, позволяют оценить масштабы и географию возникающих кризисов, способных спровоцировать серьезную нестабильность.
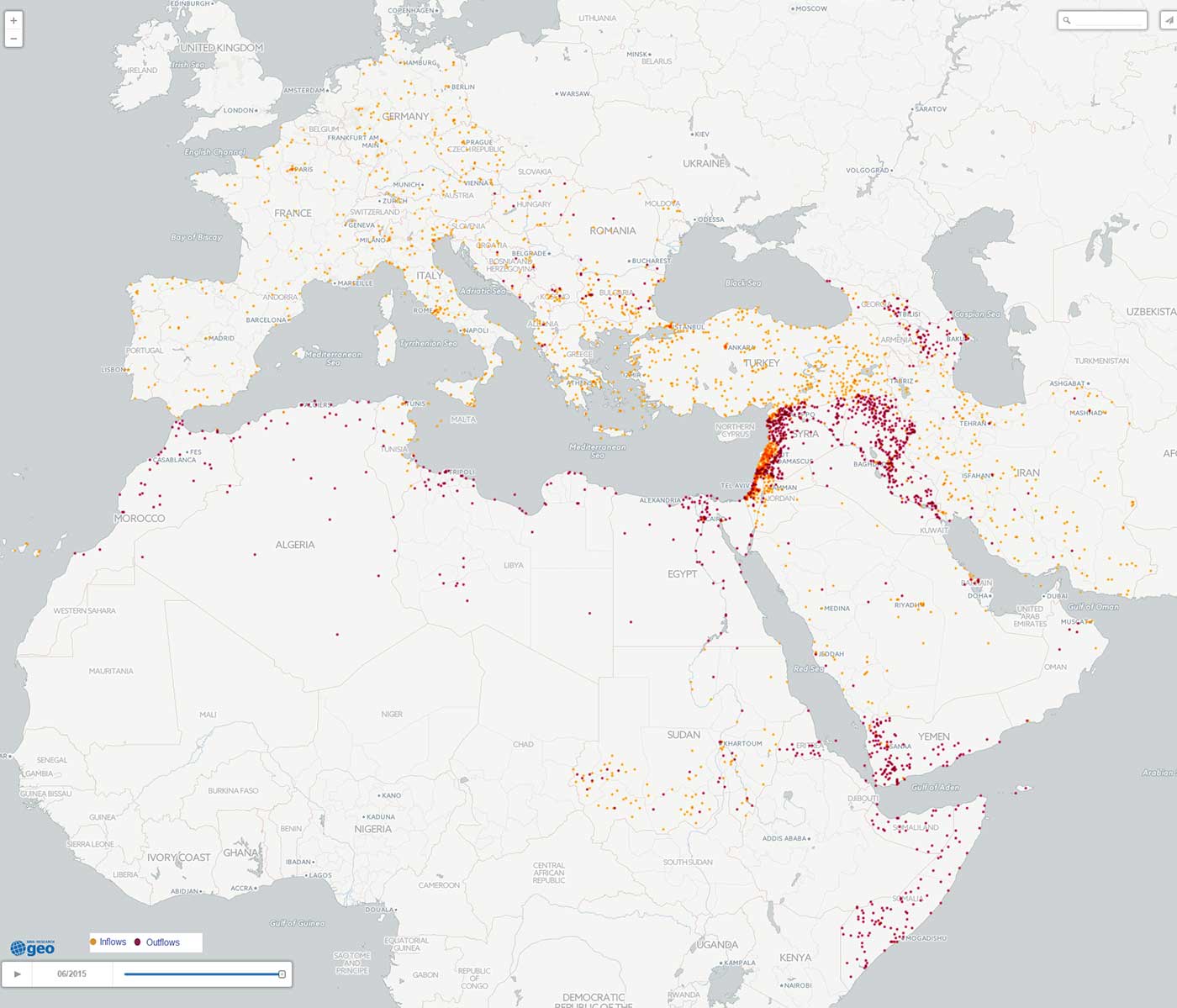
Рисунок 4. Карта притока и оттока беженцев в Европе и Северной Африке в период с 14 января по 15 июня 2015 года.
Будущее исследований
Проект GDELT – это широкое разнообразие схем данных, совместное использование как исторических данных, так и данных реального времени, внутренняя обработка и свободный доступ к наборам данных, содержащим десятки триллионов строк. Для нас этот проект представляет будущее исследований в таких областях, как социальные науки, которые традиционно опирались на «маленькие данные». Теперь подобным дисциплинам доступны также и большие данные: облачные сервисы, такие как BigQuery, возьмут на себя масштабирование и управление данными, а исследователи смогут посвятить себя поиску ответов на вопросы, которые дают новое понимание и вдохновляют инновации.