
8 способов объединения (JOIN) таблиц в SQL. Часть 1
Полуобъединение («SEMI» JOIN)
В реляционной алгебре существует операция полуобъединения (semi join), которая, к сожалению, не имеет синтаксического представления в SQL. Если бы синтаксис для данной операции существовал, вероятно, он имел бы следующий вид: LEFT SEMI JOIN и RIGHT SEMI JOIN, аналогичный реализованному в Cloudera Impala.
Что же представляет собой операция «SEMI» JOIN? Рассмотрим следующий воображаемый запрос:
SELECT * FROM actor LEFT SEMI JOIN film_actor USING (actor_id)
В результате данного запроса мы хотим получить всех актеров, снимавшихся в фильмах, но при этом нам не нужны сами фильмы. Более того, мы не хотим, чтобы данный актер появлялся в результате несколько раз (по одному разу на каждый фильм, в котором он играл), мы хотим получить каждого актера только один (или ноль) раз.
«Semi» – это латинское слово, обозначающее «половину». То есть данная операция реализует «половину объединения», в данном случае, левую половину.
В SQL мы можем использовать два варианта альтернативного синтаксиса, чтобы реализовать операцию «SEMI» JOIN.
Альтернативный синтаксис: EXISTS
Представленный ниже вариант является более мощным и чуть более многословным:
SELECT *
FROM actor a
WHERE EXISTS (
SELECT * FROM film_actor fa
WHERE a.actor_id = fa.actor_id
)
Мы извлекаем всех актеров, для которых существует (exists) фильм, то есть актеров, сыгравших хотя бы в одном в фильме. При рассмотрении данного синтаксиса (где код, реализующий «SEMI» JOIN, помещен в предложении WHERE) сразу становится очевидно, что мы можем получить в результате каждого актера максимум один раз.
Следует отметить, что в данном синтаксисе отсутствует ключевое слово JOIN. Несмотря на это, большинство СУБД способны распознать, что данный запрос выполняет именно «SEMI» JOIN, а не просто обычным образом использует предикат EXISTS(). Для примера рассмотрим план выполнения приведенного выше запроса в Oracle:
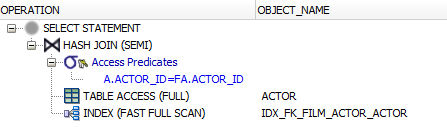
Обратите внимание, Oracle называет эту операцию «HASH JOIN (SEMI)» («SEMI» присутствует в названии).
Аналогично в PostgreSQL:
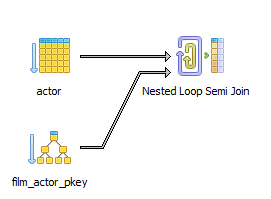
Аналогично в SQL Server:

Применение «SEMI» JOIN вместо INNER JOIN для решения поставленной задачи не только более корректно, но также обеспечивает преимущество в отношении производительности. Это объясняется тем, что после того, как найдено первое совпадение, СУБД не будет искать другие совпадения!
Альтернативный синтаксис: IN
Варианты синтаксиса на основе IN и EXISTS являются эквивалентными реализациями операции «SEMI» JOIN. Большинство СУБД (за исключением MySQL) сформируют идентичный план выполнения, как для рассмотренного выше запроса на основе EXISTS, так и для представленного ниже запроса на основе IN:
SELECT * FROM actor WHERE actor_id IN ( SELECT actor_id FROM film_actor )
Если ваша СУБД поддерживает оба описанных выше синтаксиса, вы может выбрать любой из них, руководствуясь стилистическими соображениями.
Антиобъединение («ANTI» JOIN)
Операция «ANTI» JOIN является противоположностью операции «SEMI» JOIN. Представим себе следующий воображаемый запрос:
SELECT * FROM actor LEFT ANTI JOIN film_actor USING (actor_id)
В результате этого запроса мы хотим получить всех актеров, которые не сыграли ни в одном фильме. К сожалению, данная операция также не имеет специального синтаксиса в SQL, но мы можем реализовать ее с помощью NOT EXISTS.
Альтернативный синтаксис: NOT EXISTS
Следующий запрос выполняет поставленную задачу:
SELECT * FROM actor a WHERE NOT EXISTS ( SELECT * FROM film_actor fa WHERE a.actor_id = fa.actor_id )
(Опасный) альтернативный синтаксис: NOT IN
Будьте осторожны! В то время как синтаксисы на основе EXISTS и IN эквивалентны, синтаксисы на основе NOT EXISTS и NOT IN не эквивалентны. Это связано со спецификой NULL-значений.
В данном конкретном случае представленный ниже запрос на основе NOT IN даст тот же результат, что и предыдущий запрос на основе NOT EXISTS, поскольку таблица film_actor имеет ограничение NOT NULL для столбца film_actor.actor_id:
SELECT * FROM actor WHERE actor_id NOT IN ( SELECT actor_id FROM film_actor )
Однако если бы столбец actor_id мог содержать значения NULL, запрос оказался бы неверным. Не верите? Попробуйте выполнить следующий запрос:
SELECT * FROM actor WHERE actor_id NOT IN (1, 2, NULL)
Этот запрос не вернет никакого результата, поскольку NULL является неопределенным (UNKNOWN) значением в SQL. Таким образом, предикат можно переписать следующим образом:
SELECT * FROM actor WHERE actor_id NOT IN (1, 2, UNKNOWN)
Поскольку невозможно сказать, принадлежит ли actor_id ко множеству значений, одно из которых является неопределенным, весь предикат становится неопределенным:
SELECT * FROM actor WHERE UNKNOWN
Подробнее о трехзначной логике вы можете прочитать в этой статье.
Как сказал Лукас Эдер (Lukas Eder): «Никогда не используйте предикат NOT IN в SQL, за исключением тех случаев, когда вы указали в нем константные, не содержащие NULL значения».
Также не стоит полагаться на наличие ограничения NOT NULL, поскольку администратор базы данных может временно отключить это ограничение, и ваш запрос не будет работать. Просто используйте NOT EXISTS.
(Опасный) альтернативный синтаксис: LEFT JOIN / IS NULL
Как ни странно, некоторые люди предпочитают следующий синтаксис:
SELECT * FROM actor a LEFT JOIN film_actor fa USING (actor_id) WHERE film_id IS NULL
Этот синтаксис является корректным, поскольку мы выполняем следующее:
- Объединяем актеров и фильмы.
- Получаем всех актеров, в том числе не сыгравших ни в одном фильме (LEFT JOIN).
- Оставляем только тех актеров, которые не сыграли ни в одном фильме (film_id IS NULL).
На мой взгляд, данный вариант синтаксиса является не очень удачным, поскольку он не выражает намерение выполнить «ANTI» JOIN. Кроме того, с большой вероятностью этот запрос будет медленнее аналогов, поскольку оптимизатор СУБД не сможет распознать, что программист хочет выполнить «ANTI» JOIN. Поэтому, вместо данного варианта опять же рекомендуется использовать NOT EXISTS.
Интересную (правда, немного устаревшую) статью, в которой сравниваются три рассмотренных варианта синтаксиса, вы можете найти здесь.
Латеральное объединение (LATERAL JOIN)
Ключевое слово LATERAL появилось в стандарте SQL относительно недавно. Это ключевое слово поддерживается в PostgreSQL и Oracle. СУБД SQL Server предоставляет альтернативный синтаксис на основе ключевого слова APPLY (который лично для меня является предпочтительным). Давайте рассмотрим пример использования ключевого слова LATERAL в PostgreSQL / Oracle:
WITH
departments(department, created_at) AS (
VALUES ('Dept 1', DATE '2017-01-10'),
('Dept 2', DATE '2017-01-11'),
('Dept 3', DATE '2017-01-12'),
('Dept 4', DATE '2017-04-01'),
('Dept 5', DATE '2017-04-02')
)
SELECT *
FROM departments AS d
CROSS JOIN LATERAL generate_series(
d.created_at, -- We can dereference a column from department!
'2017-01-31'::TIMESTAMP,
INTERVAL '1 day'
) AS days(day)
И правда, вместо того, чтобы выполнять CROSS JOIN, объединяя все отделы со всеми днями, почему бы просто не сгенерировать необходимые дни для каждого отдела? Именно эту задачу и выполняет LATERAL. Ключевое слово LATERAL применяется в качестве префикса для правого операнда любой операции JOIN (в том числе INNER JOIN, LEFT OUTER JOIN и т.д.) и позволяет правому операнду получить доступ к столбцам левого операнда.
Безусловно, здесь больше нет связи с реляционной алгеброй, однако в некоторых случаях подзапрос может быть настолько сложным, что этот подход является единственным способом его использования.
Другим распространенным практическим примером является ситуация, в которой мы хотим объединить результат «топ N» запроса с обычной таблицей. В частности, мы можем запросить каждого актера и 5 его самых кассовых фильмов:
SELECT a.first_name, a.last_name, f.* FROM actor AS a LEFT OUTER JOIN LATERAL ( SELECT f.title, SUM(amount) AS revenue FROM film AS f JOIN film_actor AS fa USING (film_id) JOIN inventory AS i USING (film_id) JOIN rental AS r USING (inventory_id) JOIN payment AS p USING (rental_id) WHERE fa.actor_id = a.actor_id GROUP BY f.film_id ORDER BY revenue DESC LIMIT 5 ) AS f ON true
Получим следующий результат:

Не беспокойтесь по поводу длинного списка операций JOIN, таким образом мы просто устанавливаем связь между таблицами film и payment в базе данных Sakila:
Подзапрос вычисляет 5 самых кассовых фильмов каждого актера. Таким образом, это не «классическая» производная таблица, а коррелирующий подзапрос (correlated subquery), возвращающий более чем одну строку и один столбец. Все мы привыкли писать коррелирующие подзапросы следующим образом:
SELECT a.first_name, a.last_name, (SELECT count(*) FROM film_actor AS fa WHERE fa.actor_id = a.actor_id) AS films FROM actor AS a
Результатом представленного выше коррелирующего подзапроса является одна строка и один столбец. Если мы хотим возвратить из коррелирующего подзапроса более одной строки и/или более одного столбца, в этом нам поможет LATERAL или APPLY.
Обратите внимание, поскольку совместно с LATERAL мы использовали LEFT OUTER JOIN, для корректности синтаксиса необходимо было использовать предложение ON true. Операция OUTER JOIN с ключевым словом LATERAL всегда возвращает левый операнд JOIN, то есть мы также получаем актеров, которые не сыграли ни в одном фильме.
Свойства
Ключевое слово LATERAL не меняет семантику операции JOIN, к которой применяется. Если мы выполним операцию CROSS JOIN LATERAL, размер результата по-прежнему будет следующим:
size(result) = size(left table) * size(right table)
Это справедливо даже в том случае, если правая таблица создана построчно на основе левой таблицы.
Альтернативный синтаксис: APPLY
Разработчики SQL Server не стали использовать неоднозначное ключевое слово LATERAL, а вместо этого ввели ключевое слово APPLY (в частности, CROSS APPLY и OUTER APPLY). Ключевое слово APPLY является более обоснованным, поскольку мы действительно применяем (apply) функцию к каждой строке таблицы. Давайте представим, что у нас есть функция generate_series():
-- Use with care, this is quite inefficient! CREATE FUNCTION generate_series(@d1 DATE, @d2 DATE) RETURNS TABLE AS RETURN WITH t(d) AS ( SELECT @d1 UNION ALL SELECT DATEADD(day, 1, d) FROM t WHERE d < @d2 ) SELECT * FROM t;
Тогда мы можем использовать CROSS APPLY, чтобы вызвать эту функцию для каждого отдела:
WITH
departments AS (
SELECT * FROM (
VALUES ('Dept 1', CAST('2017-01-10' AS DATE)),
('Dept 2', CAST('2017-01-11' AS DATE)),
('Dept 3', CAST('2017-01-12' AS DATE)),
('Dept 4', CAST('2017-04-01' AS DATE)),
('Dept 5', CAST('2017-04-02' AS DATE))
) d(department, created_at)
)
SELECT *
FROM departments AS d
CROSS APPLY dbo.generate_series(
d.created_at, -- We can dereference a column from department!
CAST('2017-01-31' AS DATE)
)
Интересной особенностью данного синтаксиса является то, что, как уже было сказано, мы применяем функцию к каждой строке таблицы, и эта функция генерирует строки. Что это вам напоминает? В Java 8 мы можем реализовать это с помощью Stream.flatMap()! Рассмотрим следующий вариант использования потока:
departments.stream()
.flatMap(department -> generateSeries(
department.createdAt,
LocalDate.parse("2017-01-31"))
.map(day -> tuple(department, day))
);
Представленный выше фрагмент кода выполняет следующее:
- Таблица departments является просто Java-потоком departments.
- Мы применяем flatMap к потоку departments, используя функцию, которая генерирует кортежи для каждого отдела.
- Кортежи содержат сам отдел и день, сгенерированный из серии дней, начиная с дня создания (createdAt) отдела.
Таким образом, CROSS APPLY / CROSS JOIN LATERAL в SQL представляют собой то же самое, что и Stream.flatMap() в Java. В целом, SQL и потоки достаточно похожи. Подробнее об этом сходстве вы можете прочитать здесь.
Отметим, что мы можем применить OUTER APPLY (по аналогии с LEFT OUTER JOIN LATERAL) в том случае, когда хотим сохранить левый операнд выражения JOIN.
Объединение на основе MULTISET
Немногие СУБД поддерживают данный тип объединения (на самом деле, только Oracle), но если задуматься, это крайне полезный вариант операции JOIN, позволяющий создавать вложенные коллекции (nested collection). Если бы все СУБД поддерживали эту операцию, нам больше не понадобилось бы объектно-реляционное отображение (object-relational mapping, ORM)!
Рассмотрим гипотетический пример (на основе стандартного синтаксиса SQL, а не синтаксиса Oracle):
SELECT a.*, MULTISET ( SELECT f.* FROM film AS f JOIN film_actor AS fa USING (film_id) WHERE a.actor_id = fa.actor_id ) AS films FROM actor
Оператор MULTISET принимает коррелирующий подзапрос в качестве аргумента и агрегирует все его результирующие строки во вложенную коллекцию. Эта операция работает аналогично LEFT OUTER JOIN (где мы извлекаем всех актеров, а также все их фильмы, если они снялись в каких-либо фильмах), но вместо того, чтобы дублировать актеров в результате, мы собираем их во вложенную коллекцию.
Те же действия мы выполняли бы в ORM, при извлечении данных в следующую структуру:
@Entity
class Actor {
@ManyToMany
List films;
}
@Entity
class Film {
}
Не обращайте внимания на неполные JPA-аннотации, мы просто хотели продемонстрировать силу вложенных коллекций. В отличие от ORM, оператор MULTISET позволяет собирать во вложенные коллекции произвольные результаты коррелирующих подзапросов, а не только фактические сущности (entity). Это обеспечивает такие возможности, о которых ORM может только мечтать.
Альтернативный синтаксис: Oracle
Как мы уже говорили, Oracle поддерживает MULTISET, однако мы не можем создавать ad-hoc вложенные коллекции. По некоторым причинам, разработчики Oracle решили реализовать номинальную типизацию (nominal typing) для этих вложенных коллекций, а не обычную структурную типизацию (structural typing) в SQL-стиле. Поэтому мы должны объявить наши типы заранее:
CREATE TYPE film_t AS OBJECT ( ... ); CREATE TYPE film_tt AS TABLE OF FILM; SELECT a.*, CAST ( MULTISET ( SELECT f.* FROM film AS f JOIN film_actor AS fa USING (film_id) WHERE a.actor_id = fa.actor_id ) AS film_tt ) AS films FROM actor
Чуть более многословно, но все же решает поставленную задачу!
Альтернативный синтаксис: PostgreSQL
К сожалению PostgreSQL не поддерживает MULTISET. Однако эту проблему несложно решить с помощью массивов! Кстати, здесь мы можем использовать структурные типы! Отлично! Следующий запрос возвращает вложенный массив строк:
SELECT a AS actor, array_agg( f ) AS films FROM actor AS a JOIN film_actor AS fa USING (actor_id) JOIN film AS f USING (film_id) GROUP BY a
Результат является объектно-реляционной мечтой каждого! Мы получили вложенные записи и коллекции (и всего два столбца):
actor films
-------------------- ----------------------------------------------------
(1,PENELOPE,GUINESS) {(1,ACADEMY DINOSAUR),(23,ANACONDA CONFESSIONS),...}
(2,NICK,WAHLBERG) {(3,ADAPTATION HOLES),(31,APACHE DIVINE),...}
(3,ED,CHASE) {(17,ALONE TRIP),(40,ARMY FLINTSTONES),...}
Если это вас не впечатляет, тогда что же?
Заключение
Итак, мы рассмотрели множество различных способов объединения таблиц в SQL. Надеемся, вы нашли в этой статье пару новых трюков. Впрочем, JOIN – это лишь одна из многих очень полезных операций SQL.
Перевод Станислава Петренко