

Мауриц Эшер (Maurits Escher)
Дуглас Хофштадтер (Douglas Hofstadter) в своей книге «Я – странная петля» («I am a Strange Loop») высказал следующую идею:
«В конечном счете, мы – это воспринимающие сами себя, изобретающие сами себя, замкнутые в себе миражи, являющиеся маленькими чудесами самореференции».
«In the end, we are self-perceiving, self-inventing, locked-in mirages that are little miracles of self-reference.»
В этой книге автор рассматривает механизм самореференции, как уникальное свойство разума. Странная петля (strange loop) – это циклическая система, охватывающая несколько уровней иерархии. Двигаясь по этой петле, в итоге мы попадаем в исходную точку.
По случайному совпадению или нет, эта «странная петля», по сути, является фундаментальной основой того, что Ян Лекун (Yann LeCun) назвал «самой крутой идеей в машинном обучении за последние 20 лет».
Цикличность не свойственна системам глубокого обучения. Такие системы традиционно создавались в виде структуры, состоящей из последовательных вычислительных слоев. Однако сейчас мы начинаем осознавать, что применение обратных связей открывает удивительные новые возможности для автоматических систем. Уже сегодня исследователи обучают узкоспециализированные интеллектуальные системы, превосходящие возможности человека.
Мое первое воспоминание об эффективных системах глубокого обучения с применением обратных связей относится к концепции лестничных сетей (ladder network). Лестничные сети были представлены достаточно давно, еще в июле 2015 года. На рисунке ниже показана их архитектура:
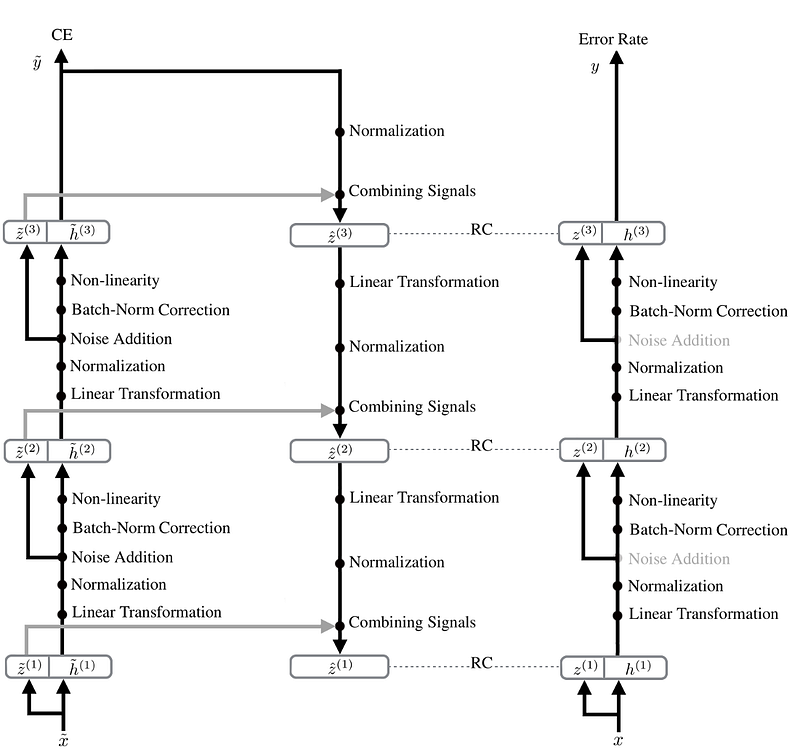
«Deconstructing the Ladder Network Architecture»
Концепция лестничной сети предусматривает одну петлю вверх и вниз по слоям, за которой следует один финальный проход в прямом направлении. На момент публикации система демонстрировала выдающиеся показатели. Концепция была усовершенствована авторами в середине 2016 года:
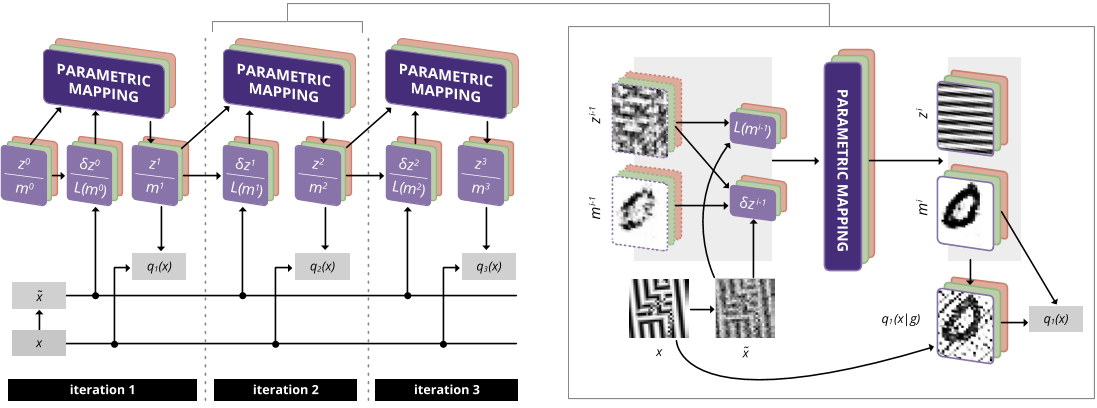
Tagger: Deep Unsupervised Perceptual Grouping
Новый вариант объединял в себе несколько лестничных сетей. Полученная в результате сеть приобрела способностью группировать объекты на изображениях.
Генеративные соревновательные сети (ГСС, generative adversarial network, GAN) также имеют свой цикл. Этот цикл является не элементом архитектуры, а скорее частью процесса обучения. В процессе обучения ГСС участвует генеративная и дискриминативная сеть, соревнующиеся друг с другом. Дискриминатор старается правильно классифицировать данные, созданные генератором. Генератор старается подобрать такие данные, которые позволят «обмануть» дискриминатор. В результате генератор и дискриминатор обучаются все лучше и лучше выполнять свою задачу. ГСС выполняют своего рода тест Тьюринга и в настоящее время являются лучшими генеративными моделями для изображений.
Здесь, по сути, имеет место механизм обратной связи в форме нейронной сети (дискриминатора), благодаря которой генератор получает возможность создавать более сложные данные (т.е. более реалистичные изображения). Существует множество примеров ГСС, генерирующих очень реалистичные изображения.
Более новые архитектуры развивают описанные выше идеи и применяют ГСС совместно с лестничными сетями:
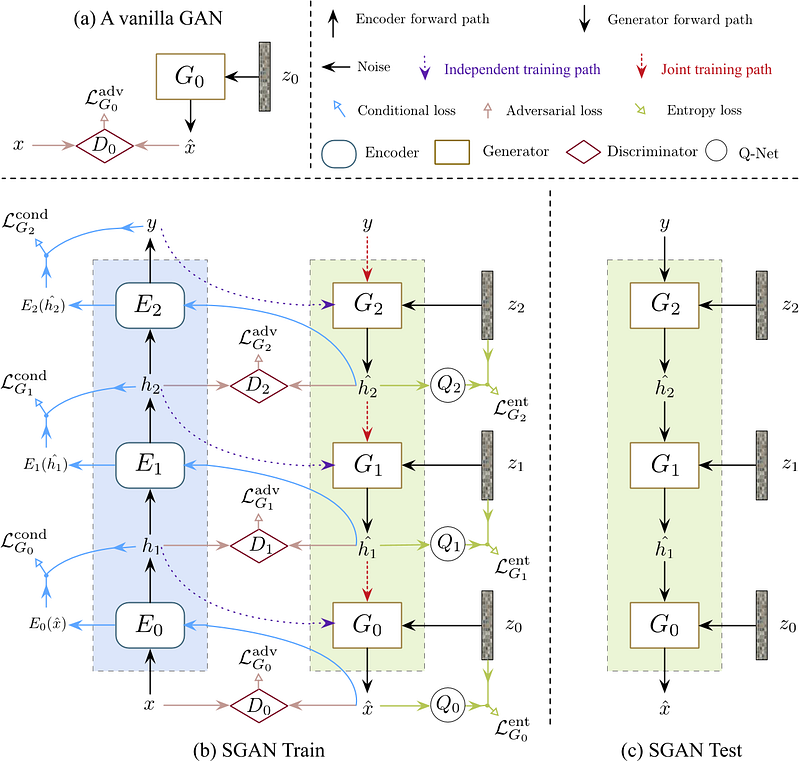
Stacked Generative Adversarial Networks
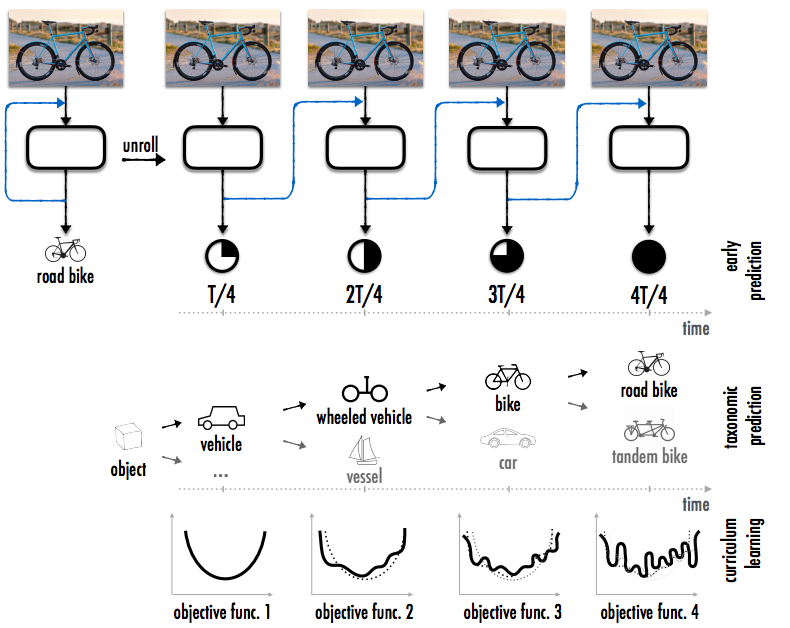
Новейшие исследования в области инкрементного обучения (incremental learning) также связаны с применением циклов. Один из недостатков, свойственных традиционным системам глубокого обучения, заключается в том, что обучение на новых данных может лишить сеть приобретенных ранее возможностей. То есть сеть «забывает» то, чему она обучилась ранее. Чтобы решить эту проблему, ученые из Стэнфорда разработали архитектуру сети с обратной связью (feedback networks). В рамках этого исследования были рассмотрены различные типы сетей, в которых выходной сигнал подается на вход, при этом внутреннее представление формируется поэтапно:
В одном из последних исследований (март 2017) ученые из Калифорнийского университета в Беркли создали систему, позволяющую реализовать удивительные преобразования изображений. Данная система, основанная на ГСС и новом типе регуляризации, получила название CycleGAN. Результаты ее работы впечатляют:

Например, система может преобразовать картину в реалистичную фотографию. Кроме того, она способна выполнять «семантический перевод». В частности, для нее не составит труда превратить лошадей в зебр или изменить время года на фотографии.
Суть подхода заключается в использовании циклически согласованной функции потерь (cycle-consistency loss). Данная функция стимулирует сеть к тому, чтобы она обучилась выполнять не только прямое преобразование, но и обратное.
Основной трудностью при обучении глубоких сетей всегда являлась нехватка размеченных данных, являющихся топливом, повышающим точность моделей. Однако новые типы систем, в которых применяются циклы, позволяют решить эту проблему. Подобные системы можно сравнить с вечным двигателем, в котором постоянно возникают все новые и новые вариации размеченных данных. Как следствие, эти системы способны парадоксальным образом подпитывать сами себя новыми данными. Они играют в «игру» сами с собой и при достаточном количестве сыгранных «партий» становится экспертами в этой «игре». Аналогичный подход был применен в системе AlphaGo, которая смогла «изобрести» новые стратегии игры в го, играя против самой себя.
Наблюдая за развитием автоматических систем, оснащенных циклом обратной связи и способных имитировать множество различных сценариев (некоторые называют это «воображением»), при этом самостоятельно тестируя их корректность, можно сказать, что мы находимся на пороге создания некой чрезвычайно мощной технологии, способной в скором времени обеспечить такие возможности, о которых никто и не мечтал. Так что в следующий раз, когда вы увидите новые поразительные достижения глубокого обучения, присмотритесь, вероятно, и здесь не обошлось без странной петли.