
Мне, как консультанту, часто задают вопросы о выборе инструментов для работы с большими данными. Что лучше использовать, Python или R? Какое NoSQL хранилище является лучшим на данный момент? Как организовать озеро данных (data lake)?
Несмотря на то, что я постоянно нахожусь в курсе последних событий, я не владею информацией обо всем, что происходит в экосистеме больших данных, поскольку в сфере, охватывающей более 2000 компаний и продуктов, это не под силу ни одному специалисту.
Стремясь обеспечить доступность своих продуктов для широкой аудитории, разработчики создают API для популярных языков, с которыми работает большинство data scientist’ов: R и Python. Ряд продуктов обязан своим успехом именно хорошим интерфейсам для этих двух языков. Например, Microsoft обеспечивает возможность работы с блокнотами R и Jupyter в Azure Machine Learning. Amazon поддерживает блокноты Jupyter в EMR. И, наконец, мой любимый пример того, как все стремятся запрыгнуть в быстро идущий поезд data science: в настоящее время мы можем выполнять код на R в SAS.
Не отстает от конкурентов и Spark, который изначально имел интерфейс на Scala, но затем быстро приобрел полнофункциональный API для Python, когда data scientist’ы, не имеющие опыта работы с JVM, стали обращать свое внимание на эту платформу. В настоящее время проект находится под эгидой компании Databricks, основанной первоначальными разработчиками Spark. Конечно же, проект предлагает собственный аналитический продукт на основе блокнотов.
Мотивация в отношении SparkR очень велика. Если вы знаете R, вам не нужно переключаться на Python или Scala, чтобы создавать свои модели и использовать все преимущества Spark. Однако SparkR в своем текущем состоянии (пока еще) не обеспечивает полноценную функциональность R. Кроме того, некоторые ключевые особенности платформы свидетельствуют о том, что SparkR не очень хорошо вписывается в парадигму программирования Spark.
SparkR API: путаница DataFrame’ов
Первая проблема заключается в организации данных. DataFrame стал стандартным элементом всех языков, работающих с данными. Этот инструмент имитирует функциональность таблицы в базе данных SQL и реализован в Python, R и SAS, примеру которых последовал Spark.
В целом, таблицы – это хорошо. Таблица обеспечивает наиболее удобный для человека способ воспринимать данные и манипулировать ими. В реляционной среде работа с таблицами не вызывает никаких затруднений. Но мы сразу же сталкиваемся с проблемами, когда императивный язык программирования пытается имитировать декларативные структуры данных, особенно если эти структуры распределены по множеству машин и связаны сложными наборами инструкций.
SparkDataFrame и стандартный data.frame из R существенно отличаются:
|
Объект |
SparkDataFrame |
data.frame |
|
Обработка |
На множестве машин в кластере Spark |
На локальной машине, в памяти |
|
Код |
Пишется на R, переводится на Scala |
Пишется на R |
|
Структура |
Табличный объект, разделенный на группы строк, которые возвращаются в случайном порядке |
Табличный объект, состоящий из столбцов (векторов) одинаковой длины с заголовками |
На первый взгляд эти объекты очень похожи и позволяют выполнять аналогичные операции. Ничто в их названиях не говорит о сущности объектов. В результате путаницы, вызванной внешним сходством, решено было переименовать DataFrame в SparkDataFrame (отчасти также для того, чтобы избежать конфликта с объектом из пакета S4Vectors).
Человек, привыкший к базовой функциональности R, здесь встречается с коллизией концепций. Описать ситуацию можно с помощью следующей аналогии. Когда мы работаем с data.frame, запрос данных подобен обычному поиску словарной статьи. Но когда мы работаем со SparkDataFrame, различные слова интересующей нас словарной статьи разбросаны по разным томам Британской энциклопедии. Соответственно, мы должны просмотреть каждый том, найти нужные слова и собрать их воедино. Кроме того, слова не отсортированы в алфавитном порядке.
Давайте исследуем каждый из двух объектов, чтобы лучше разобраться в их различиях. Начнем с data.frame.
В языке R data.frame – это объект, располагающийся в оперативной памяти (in-memory) и представляющий собой список векторов одинаковой длины. Каждый столбец содержит значения одной переменной, а каждая строка – одно наблюдение.
Работая в RStudio, мы можем импортировать один из наборов данных, доступных по умолчанию:
datasets() # display available datasets attached to R
data(income) # use US family income from US census 2008
help(income) # find out more about the package
income <-income # put the data into a data.frame
> class(income) # check type
[1] «data.frame
> class(income$value) #check individual column (vector) type
[1] «integer»
str(income) # check values
‘data.frame’: 44 obs. of 4 variables:
$ value: int 0 2500 5000 7500 10000 12500 15000 17500 20000 22500 …
$ count: int 2588 971 1677 3141 3684 3163 3600 3116 3967 3117 …
$ mean : int 298 3792 6261 8705 11223 13687 16074 18662 21064 23698 …
$ prop : num 0.02209 0.00829 0.01431 0.0268 0.03144 …
Когда мы работаем с data.frame, все операции выполняются на той машине, на которой запущен процесс R, в данном случае на моем MacBook:
mbp-vboykis:~ vboykis$ ps
PID TTY TIME CMD
28239 ttys000 0:00.18 ~/R
Теперь рассмотрим SparkDataFrame

SparkDataFrame – это совсем другой зверь. Во-первых, Spark является распределенной системой. Это означает, что операции выполняются посредством множества процессов, называемых исполнителями (executor), на множестве машин кластера, называемых рабочими узлами (worker node).
Управляющий процесс называется драйвером (driver). Драйвер инициирует Spark-сессию (session), создает план выполнения (execution plan) и отправляет его на главный узел (master node), который, в свою очередь, отправляет его рабочим узлам (worker node). Другими словами, драйвер запускает метод main().
Драйвер создает SparkContext, являющийся входной точкой Spark-программы, и распределяет выполнение кода по исполнителям, расположенным на различных логических или физических узлах.
Мы пишем SparkR-код на краевом узле (edge node) кластера Hadoop. Этот код преобразуется из SparkR в JVM-процесс драйвера (поскольку Spark базируется на Scala). Затем код отправляется в слушающие JVM-процессы на каждом краевом узле. В процессе данные сериализуются и распределяются по машинам.
Наконец, когда Spark инициализирован и существует сетевое подключение, создается SparkDataFrame. На самом деле, SparkDataFrame – это представление (view) другого Spark-объекта, называемого Dataset, который является коллекцией сериализованных JVM-объектов.
Объект Dataset, то есть исходный набор инструкций, полученный в результате перевода R-кода в Spark, с помощью SparkSQL форматируется таким образом, чтобы имитировать таблицу. Вы можете посмотреть отличную презентацию одного из разработчиков SparkR по этой теме.
Кроме того, для корректного вычисления SparkDataFrame, Spark должен реализовать логику для всех серверов. Чтобы обеспечить эту возможность, SparkDataFrame, в сущности, не является данными. На самом деле, он является набором инструкций, описывающих, как получить доступ к данным и как обрабатывать их на различных узлах, то есть происхождение данных.
Ниже представлена хорошая схема операций, выполняемых при работе со SparkDataFrame:
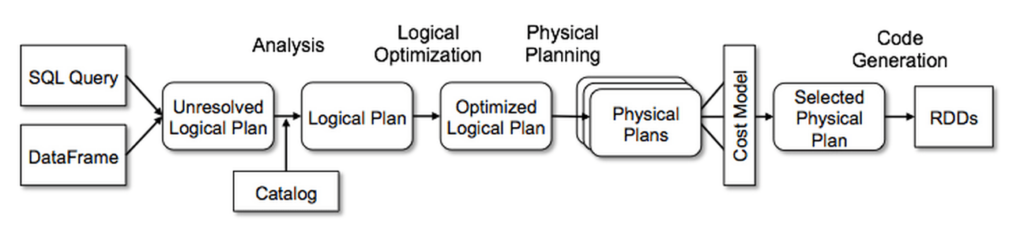
Вывод из вышесказанного заключается в том, что логика доступа к SparkDataFrame и data.frame существенно отличается. В частности, можно выделить два существенных отличия. (Код находится здесь.)
Первое из них заключается в том, что хотя Spark реализует строковую парадигму, мы не можем получить доступ к конкретным строкам SparkDataFrame.
В случае data.frame:
head(income)
value count mean prop
1 0 2588 298 0.022085115
2 2500 971 3792 0.008286185
3 5000 1677 6261 0.014310950
4 7500 3141 8705 0.026804229
5 10000 3684 11223 0.031438007
6 12500 3163 13687 0.026991970
> class(income)
[1] «data.frame»
> income[row.names(income)==2,]
value count mean prop
2 2500 971 3792 0.008286185
А теперь попробуем выполнить эквивалентную операцию, используя SparkR:
sdf <- as.DataFrame(income) #convert to SparkDataFrame
sdf #check out type
SparkDataFrame[value:int, count:int, mean:int, prop:double]
head(sdf) #same function as on local data
income[row.names(income)==2,]
Error in sdf[row.names(income) == 2, ] :
Expressions other than filtering predicates are
not supported in the first parameter of extract operator [ or subset() method.
Причина ошибки находится здесь. Это означает, что мы можем выполнять только столбцовые операции с исходным DataFrame’ом. Следовательно, мы должны пройти по всему SparkDataFrame, применяя изменения к тому, что в R являлось бы эквивалентом вектора.
Такое положение вещей приводит к необходимости применять неудобные обходные пути для выполнения стандартных задач, таких как заполнение пустых значений. Например, мы хотим заполнить пустые значения средним по столбцу. Работая с data.frame, мы можем сделать это следующим образом:
m <- matrix(sample(c(NA, 1:10), 100, replace = TRUE), 10)
d <- as.data.frame(m)
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 1 4 10 3 1 4 9 6 3 1
2 3 4 10 5 2 3 7 1 9 NA
3 10 NA 5 NA 10 9 3 NA NA 5
4 1 9 4 3 3 2 8 7 7 8
5 6 3 2 6 5 10 5 10 10 9
6 5 9 7 10 5 6 8 3 4 10
7 9 10 3 6 6 4 6 7 7 8
8 5 9 8 4 8 2 2 9 9 NA
9 1 5 1 8 7 3 8 1 NA 4
10 10 2 9 10 1 3 8 8 5 6
for(i in 1:ncol(d)){
d[is.na(d[,i]), i] <- mean(d[,i], na.rm = TRUE)
}
d
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 1 4.000000 10 3.000000 1 4 9 6.000000 3.00 1.000
2 3 4.000000 10 5.000000 2 3 7 1.000000 9.00 6.375
3 10 6.111111 5 6.111111 10 9 3 5.777778 6.75 5.000
4 1 9.000000 4 3.000000 3 2 8 7.000000 7.00 8.000
5 6 3.000000 2 6.000000 5 10 5 10.000000 10.00 9.000
6 5 9.000000 7 10.000000 5 6 8 3.000000 4.00 10.000
7 9 10.000000 3 6.000000 6 4 6 7.000000 7.00 8.000
8 5 9.000000 8 4.000000 8 2 2 9.000000 9.00 6.375
9 1 5.000000 1 8.000000 7 3 8 1.000000 6.75 4.000
10 10 2.000000 9 10.000000 1 3 8 8.000000 5.00 6.000
Когда же перед нами SparkDataFrame, мы не можем выполнить эту операцию подобным образом и должны использовать обходное решение. Это связано с тем, что в результате секционирования данных мы не можем выполнять агрегацию. Мы увидим следующее сообщение об ошибке:
Error in sdfD[is.na(sdfD[, i]), i] <- mean(d[, i], na.rm = TRUE) :
object of type ‘S4’ is not subsettable
In addition: Warning message:
In is.na(sdfD[, i]) :
is.na() applied to non-(list or vector) of type ‘S4’
Таким образом, мы должны осуществить заполнение для каждого столбца с помощью fillna, используя список:
mean(sdfD$v10)
your_average<-as.list(head(select(sdfD,mean(sdfD$v10))))
sdfFinal<-fillna(sdfD,list(«v10» = your_average[[1]]))
sdfFinal
head(sdfFinal)
Можно отметить, что в данном случае потребовалось меньше кода (как минимум для одного этапа), но этот подход намного труднее понять, кроме того, для реализации подобных эквивалентных операций приходится серьезно порыться в документации.
Второе существенное отличие касается возвращаемых результатов. Например, если мы хотим вывести на экран содержимое data.frame, мы всегда будем получать одинаковый результат, повторяя эту операцию. Однако, если речь идет о SparkDataFrame, здесь ситуация обстоит по-другому. Распределенная природа и секционирование данных в Spark, приводят к тому, что при работе со SparkDataFrame, мы каждый раз получаем слегка отличающееся подмножество данных, в зависимости от того, как быстро завершаются процессы и какие действия предписывает план выполнения.
То, что происходит, когда данные возвращаются из Spark, хорошо иллюстрирует следующая шутка:
«Some people, when confronted with a problem, think “I know, I’ll use multithreading”. Nothhw tpe yawrve o oblems.»
«Столкнувшись с проблемой, некоторые люди думают: «Я знаю, я применю многопоточность». Тпеерь у инх две лемыпроб».
Вдобавок ко всему сказанному, мы можем переключаться между SparkDataFrame и data.frame, даже не подозревая об этом, пока Spark не выдаст исключение.
Кроме того, мы можем написать визуально очень похожие функции для разных объектов. Как результат, то, что в теории должно быть большим преимуществом, обеспечивающим портируемость, становится большим неудобством. Взгляните на следующий пример:
model <- glm(F ~ x1+x2+x3, df, family = «gaussian»)
model <- glm(F ~ x1+x2+x3,data=df,family=gaussian())
Где обычный R, а где Spark? Если забыть синтаксис, можно легко запутаться. В результате, широкое распространение получила практика использования следующих префиксов в именах объектов: sdf для SparkDataFrame и rdf для data.frame.
sdfmodel <- glm(F ~ x1+x2+x3, df, family = «gaussian»)
rdfmodel <- glm(F ~ x1+x2+x3,data=df,family=gaussian())
Рассмотренные особенности могут приводить к путанице, особенно если мы создаем большое количество объектов или передаем их из одной среды в другую.
Функциональность, адаптация и темпы развития
Проект SparkR молодой и, вероятно, развивающийся. Это означает, что функциональность постоянно расширяется. Впрочем, похоже, что SparkR имеет более низкий приоритет по сравнению с другими языками экосистемы Spark.
На слайдах Матея Захарии (Matei Zaharia), подготовленных для SparkSummit, вы можете увидеть, что в течение последних нескольких лет приоритетными направлениями для компании Databricks, контролирующей разработку Spark, были: глубокое обучение, потоковая обработка и оптимизация производительности SparkSQL (что затрагивает Scala, Python и R). Соответственно, разработка SparkR API имеет не слишком высокий приоритет. Это логично: в языковом спектре Spark, доля использования R составляет лишь 20%, что приводит к проблеме курицы и яйца. Пока эта доля не увеличится, нет оснований существенно увеличивать объемы ресурсов, направленных на развитие этого направления. В то же время, пока не будет выделено больше ресурсов, количество пользователей не увеличится.
Если не принимать во внимание заявления руководства проекта, можем ли мы реально оценить, действительно ли SparkR развивается, и стоит ли использовать его в своем проекте? Чтобы ответить на этот вопрос, я проанализировала исходный код Spark (зеркало основного репозитория находится на GitHub).
Выполнив запрос с помощью cURL, мы видим, что доля SparkR составляет менее 4% от всего исходного кода Spark (по количеству строк кода):
# pull all languages used in the Spark repo
curl -u veekaybee -G «https://api.github.com/repos/apache/spark/languages»
Enter host password for user ‘veekaybee’:
{
«Scala»: 22832829,
«Java»: 2948574,
«Python»: 2210161,
«R»: 1047322,
«Shell»: 155167,
«JavaScript»: 140987,
«Thrift»: 33605,
«ANTLR»: 32969,
«Batchfile»: 24294,
«CSS»: 23957,
«Roff»: 14420,
«HTML»: 9800,
«Makefile»: 7774,
«PLpgSQL»: 6763,
«SQLPL»: 6233,
«PowerShell»: 3751,
«C»: 1493
}

Безусловно, само по себе это число ни о чем не говорит. Мы можем найти несколько объяснений:
-
Большая часть кода, обеспечивающего взаимодействие R и Scala, написана на Scala. В отношении Python мы наблюдаем такую же тенденцию. Несмотря на широкую популярность PySpark, Python-код составляет всего 7% от общего объема исходного кода Spark.
-
Разработка SparkR началась совсем недавно, как следствие, потребуется значительное количество времени, чтобы догнать по объему код на Scala.
-
R более лаконичен, чем Scala и даже Python. Соответственно, для реализации одних и тех же задач требуется меньше строк R-кода.
Чтобы еще детальнее проанализировать вопрос, я клонировала репозиторий Spark и извлекла сообщения, сопровождающие коммиты. Скрипт на Python находится здесь.
Эти сообщения очень хорошо организованы (как минимум, начиная с 2013 года), поскольку правила сообщества разработчиков Spark предписывают подробное документирование вкладов и стандартизацию pull-запросов:
«The PR title should be of the form [SPARK-xxxx][COMPONENT] Title, where SPARK-xxxx is the relevant JIRA number, COMPONENT is one of the PR categories shown at spark-prs.appspot.com and Title may be the JIRA’s title or a more specific title describing the PR itself.»
«Заголовок pull-запроса должен иметь следующую форму: [SPARK—xxxx][КОМПОНЕНТ] Заголовок, где SPARK—xxxx – это соответствующий JIRA-номер; КОМПОНЕНТ – это одна из категорий pull-запросов, представленных на spark—prs.appspot.com; Заголовок может быть JIRA-заголовком или более специфичным описанием pull-запроса».
Проанализировав количество pull-запросов по категориям на указанном сайте, мы видим, что существенный объем работ выполняется в направлении SQL, при этом вклад в R сравнительно небольшой. Впрочем, эта информация также не дает нам полную картину ситуации.

На рисунке ниже представлена диаграмма количества коммитов в проекте Spark на различных этапах развития:

Теперь сравним PySpark и SparkR:

Я не использовала данные за 2017 год, поскольку он еще не завершен. На удивление, диаграмма показывает, что разработка SparkR была более активной, чем разработка PySpark за одни и те же периоды. Однако эта информация также не позволяет нам сделать конкретные выводы. Означает ли это, что большее количество ресурсов направляется на развитие SparkR? Или же дело в том, что данная часть проекта очень молода, и просто требует большего вклада, чтобы догнать другие компоненты?
Трудно сказать. Однако, работая со SparkR, легко заметить отсутствие ряда функций, доступных R. Одной из самых важных отсутствующих функций является apply.
Функция apply в R является удобной альтернативой циклическому проходу по data.frame с целью взаимодействия с отдельными ячейками. (Также позволяет работать с измерениями, то есть, например, со строками или столбцами.) SparkR не может работать с объектами на уровне отдельных ячеек, в виду своей распределенной природы, а также по причине передачи данных между JVM-процессами. Это означает, что реализация apply только начинается.
Существуют родные функции SparkR, gapply и dapply, но ни одна из них не может в точности реализовать работу apply. Также существует множество обходных путей, которые не всегда обеспечивают желаемый результат.
Наконец, следует отметить, что объекты моделей, даже близко не обладают уровнем доступности своих аналогов в R. Например, стандартным результатом кластеризации методом k-средних (k-means clustering) в R является внутрикластерная сумма квадратов (within-cluster sum of squares, WSS) и соответствующие компоненты, при этом объекты модели легко доступны. (Сравните R API и SparkR API для метода k-средних.)
set.seed(20)
irisCluster <- kmeans(iris[, 3:4], 3, nstart = 20)
irisCluster
K-means clustering with 3 clusters of sizes 46, 54, 50
Cluster means:
Petal.Length Petal.Width
1 5.626087 2.047826
2 4.292593 1.359259
3 1.462000 0.246000
Clustering vector:
[1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[35] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[69] 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1
[103] 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 2 1 1 2 2 1 1 1 1 1 1 1 1
[137] 1 1 2 1 1 1 1 1 1 1 1 1 1 1
Within cluster sum of squares by cluster:
[1] 15.16348 14.22741 2.02200
(between_SS / total_SS = 94.3 %)
Available components:
[1] «cluster» «centers» «totss» «withinss»
[5] «tot.withinss» «betweenss» «size» «iter»
[9] «ifault»
SparkR не дает на выходе WSS, и не обеспечивает доступ к объектам модели. Это означает, что требуется обходное решение, чтобы определить оптимальный размер кластера:
model <- spark.kmeans(df, ~ Petal_Length + Petal_Width, k = 3, initMode = «random»)
summary(model)
[1] 3
$coefficients
Petal_Length Petal_Width
1 4.925253 1.681818
2 1.492157 0.2627451
$size
$size[[1]]
[1] 99
$size[[2]]
[1] 51
$size[[3]]
[1] 0
$cluster
SparkDataFrame[prediction:int]
$is.loaded
[1] FALSE
$clusterSize
[1] 2
## Workaround for WSS:
wss <- (nrow(rdfsample)-1)*sum(apply(rdfsample,2,var))
for (i in 1:9999) wss[i] <- sum(
kmeans(rdfsample, centers=i)$withinss)
plot(1:9999,
wss,
ENGINE=»b»,
xlab=»Number of Clusters»,
ylab=»Within groups sum of squares», xlim=c(0,10))
Невозможность визуализации данных
Визуализация – это ключевой инструмент в области data science, обеспечивающий исследование и понимание данных. R очень хорошо справляется с этой задачей. Если я работаю над небольшим проектом, который помещается на моем ноутбуке и не имеет внешних зависимостей, как правило, для визуализации я выбираю R, а не Python. Несмотря на то, что Python предлагает множество вариантов визуализации, они не так хорошо проработаны, как средства R.
Для SparkR существует порт библиотеки ggplot2. К сожалению, этот проект не обновлялся в течение года и более не совместим с последней версией Spark.
Таким образом, если мы хотим визуализировать какие-либо данные, мы должны поместить их в data.frame. В целом, это логично: Spark обычно работает с сотнями тысяч или миллионами строк, поэтому мы должны как-то обобщить данные перед их визуализацией. Но даже когда мы обобщаем, мы не можем визуализировать подмножество в SparkR, прерывая рабочий процесс.
Потенциально мы можем воспользоваться блокнотом Zeppelin, но это потребует дополнительной конфигурации.
Ни один из перечисленных вариантов не является оптимальным для исследовательского анализа данных, который является ключевым при работе с данными в любой системе.
Безусловно, следует отметить, что визуализация неидеальна во всех языках Spark, кроме PySpark, где есть Plotly.
Сложность отладки
Когда локальный R-код преобразуется в SparkDataFrame, выполняется множество действий.
-
R открывает порт и ждет подключений.
-
SparkR устанавливает подключения.
-
Каждый вызов SparkR отправляет сериализованные данные по локальному подключению и ожидает ответа.
-
Бэкенд обрабатывает запросы.
-
R отправляет JVM сериализованные двоичные данные.
-
Типы преобразуются в списки.
-
Метод и аргументы сериализуются и отправляются в бэкенд.
-
Осуществляется поиск метода и его выполнение.
Следовательно, при наличии ошибки в нашем коде, она может проявиться на одном из следующих этапов:
-
Обработка начального R-кода.
-
Сериализация данных для SparkR.
-
Преобразование для JVM.
-
Перемещение от драйвера к исполнителям.
-
Выполнение фактического задания (job) Spark.
-
Обработка результатов.
Это абсолютно незнакомая парадигма для пользователей R, в частности для тех, кто не сталкивался с распределенными вычислениями. Таким пользователям придется изучить существенный объем материала, вероятно, больший, чем инженерам без статистических навыков, приходящим из других языков. Ввиду наличия процессов сериализации и десериализации, специалист должен понимать тонкости различных уровней взаимодействия, чтобы эффективно отлаживать ошибки.
Причиной проблемы может быть: синтаксис SparkR, например, неподдерживаемая функция; сериализация в JVM-код; сеть; ошибки в коде самого SparkR API.
Чтобы научиться находить причины ошибок, необходимо освоить стектрейс Java, который существенно отличается от сообщений об ошибках, генерируемых R.
Неполная документация
Рассмотренные выше проблемы приводят к мысли о том, что R не слишком подходит для работы со Spark. Кроме того, ситуацию усугубляют пробелы в документации.
Как отмечает Холден Карау (Holden Karau) в книге «High Performance Spark», документация Spark развивается неравномерно. Как и у большинства молодых проектов, основная ее часть сосредоточена либо в исходном коде, либо на странице проекта.
Функции SparkR API документированы достаточно хорошо, хотя и не настолько подробно, как в случае PySpark или Scala. В то же время общая документация по работе со SparkR содержит недостаточное количество примеров. Кроме того, в ней отсутствует описание некоторых важных особенностей, в результате чего начинающим достаточно трудно сориентироваться. Вероятно, труднее всего приходится новичкам, пришедшим из области статистических вычислений, которые вынуждены одновременно вникать в тонкости работы Spark и SparkR.
Самая серьезная проблема в документации, которую я обнаружила, заключается в отсутствии четкой информации о том, что контекст SparkSQL не рекомендуется использовать (deprecated) в Spark 2.0:
«Spark’s SQLContext and HiveContext have been deprecated to be replaced by SparkSession. Instead of sparkR.init(), call sparkR.session() in its place to instantiate the SparkSession. Once that is done, that currently active SparkSession will be used for SparkDataFrame operations.»
«Вместо SQLContext и HiveContext рекомендуется использовать SparkSession. Чтобы создать экземпляр SparkSession, вместо вызова sparkR.init() необходимо выполнить вызов sparkR.session(). Когда это будет сделано, эта активная в данный момент сессия SparkSession будет использоваться для выполнения операций со SparkDataFrame».
«The sqlContext parameter is no longer required for these functions: createDataFrame, as.DataFrame, read.json, jsonFile, read.parquet, parquetFile, read.text, sql, tables, tableNames, cacheTable, uncacheTable, clearCache, dropTempTable, read.df, loadDF, createExternalTable.»
«Параметр sqlContext больше не требуется для следующих функций: createDataFrame, as.DataFrame, read.json, jsonFile, read.parquet, parquetFile, read.text, sql, tables, tableNames, cacheTable, uncacheTable, clearCache, dropTempTable, read.df, loadDF, createExternalTable».
На StackOverflow можно найти массу ведущих в тупик ответов, ссылающихся на Spark 1.6.
Еще одной проблемой, на которую я потратила много времени, являются конфликты имен. Информация о них должна быть более доступна.
Заключение
SparkR является многообещающим проектом, который открывает путь к распределенным вычислениям для data scientist’ов, привыкших к R и RStudio. Однако проблема заключается в том, что R и Spark имеют принципиально различные парадигмы, и до конца неясно, имеет ли смысл стараться их объединить.
Надеюсь, что в дальнейшем проект SparkR будет располагать достаточным количеством ресурсов, необходимых для его развития, и что основные проблемы, такие как недоступность объектов моделей и пробелы в документации, будут быстро решены.
1 комментарий
[…] https://datareview.info/article/dolzhen-li-spark-imet-api-dlya-r/ […]