
В этой статье мы рассмотрим Spark SQL и выясним, почему этот инструмент является предпочтительным, когда речь идет об аналитике реального времени. Spark SQL – это модуль Apache Spark, интегрирующий реляционную обработку данных и процедурный API Spark. Spark SQL является частью ядра Spark с версии 1.0. Он может работать совместно с Hive (HiveQL/SQL) или замещать его. Кроме того, модуль способен взаимодействовать с инструментами бизнес-аналитики.
Для работы с модулем можно использовать Python, Scala и Java. Благодаря Spark SQL, функционал фреймворка получает два ключевых дополнения. Во-первых, модуль обеспечивает тесную интеграцию между реляционной и процедурной обработкой данных посредством интеграции декларативного DataFrame API и процедурного API Spark. Во-вторых, он включает в себя расширяемый оптимизатор, созданный на языке Scala, обладающем широкими возможностями сопоставления с образцом (pattern matching), что позволяет легко формировать правила, управлять генерацией кода и создавать расширения.
Предназначение Spark SQL
Несмотря на то, что реляционный подход может быть использован для решения задач в области больших данных, применительно ко многим из них одного этого подхода недостаточно. До недавнего времени реляционный и процедурный подходы существовали независимо друг от друга, вынуждая разработчиков выбирать из них какой-либо один. Теперь, благодаря Spark SQL, оба подхода могут использоваться совместно.
Spark SQL поддерживает реляционную обработку как в рамках программ Spark (посредством RDD), так и применительно ко внешним источникам данных. Он также способен взаимодействовать с новыми источниками данных, включая слабоструктурированные данные и внешние базы данных, поддерживающие федеративные запросы (federated query).
Как говорится: «Самый быстрый способ прочитать данные – НЕ читать их вообще». Spark SQL реализует данную парадигму с помощью следующих подходов:
-
Преобразование данных в более эффективные форматы (с точки зрения хранилища, сети и операций ввода/вывода), в частности, в различные форматы, ориентированные на столбцы (columnar format).
-
Секционирование данных.
-
Уменьшение количества операций чтения на основе статистики.
-
Оптимизация предикат.
-
Выполнение оптимизации как можно позже, когда доступна вся информация о конвейерах данных.
Spark SQL и DataFrame используют оптимизатор запросов Catalyst для интеллектуального планирования выполнения запросов.
Spark Streaming + Spark SQL и DataFrame
Spark SQL может поддерживать пакетный и потоковый SQL. Ядро Spark обеспечивает обработку пакетных нагрузок посредством RDD. RDD могут ссылаться на статические наборы данных, а с помощью обширного API Spark можно манипулировать RDD в оперативной памяти с применение «ленивых» вычислений.
Давайте кратко рассмотрим, что такое RDD и DStream. Понимание этих базовых концепций понадобится нам для дальнейшего изложения.
Spark оперирует данными в форме RDD. RDD (resilient distributed dataset, отказоустойчивый распределенный набор данных) – это распределенная структура данных, размещаемая в оперативной памяти. Каждый RDD представляет собой фрагмент данных, распределенных по узлам кластера. RDD являются неизменяемыми структурами, поэтому после преобразований создаются новые RDD. RDD обрабатываются параллельно с помощью таких преобразований/действий, как отображение, фильтрация и др. Эти операции выполняются одновременно во всех разделах (partition). RDD являются отказоустойчивыми: если раздел теряется в результате сбоя узла, он может быть восстановлен из исходных источников.
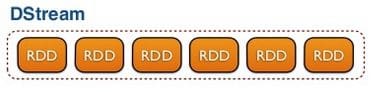
Spark Streaming реализует абстракцию под названием DStream (discretized stream, дискретизированный поток), представляющую собой непрерывный поток данных. DStream может быть создан следующим образом: из потока входных данных; на основе таких источников, как Kafka или Flume; или посредством выполнения операций с другими DStream. По сути, DStream – это последовательность RDD.
RDD, созданный посредством DStream, можно преобразовать в DataFrame и выполнять к нему запросы с помощью SQL. Доступ к потоку можно предоставить для любого внешнего приложения, поддерживающего SQL, с помощью JDBC-драйвера. Пакеты потоковых данных хранятся в памяти узла. Эти данные можно интерактивно запрашивать, используя SQL или API Spark.
StreamSQL – это компонент Spark, объединяющий Catalyst и Spark Streaming для выполнения SQL-запросов к DStream. StreamSQL расширяет SQL, обеспечивая поддержку следующих потоковых операций:
-
Выборка (SELECT) из потока для вычисления функций или фильтрации ненужных данных (с помощью условия WHERE).
-
Соединение (JOIN) потока с одним или несколькими наборами данных для создания нового потока.
-
Применение оконных функций и выполнение агрегаций. Поток можно настроить таким образом, чтобы он создавал наборы данных ограниченного размера. С помощью оконных функций можно выполнять сложный отбор сообщений на основе значений полей. После создания ограниченного пакета можно выполнять аналитику.
Компоненты Spark SQL
Ядро Spark SQL
-
Выполнение запросов.
-
Чтение данных в различных форматах: Parquet, JSON, Avro и др.
-
Чтение SQL— и NoSQL-источников данных.
Поддержка Hive
-
HQL, MetaStore, сериализация/десериализация (SerDes), пользовательские функции (UDF).
Оптимизатор Catalyst
-
Оптимизация реляционной алгебры и выражений.
-
Оптимизация запросов.
Преимущества Spark SQL
Spark SQL реализует концепцию интегрированной платформы, в рамках которой нет необходимости в перемещении данных вне кластера. Также не требуется установка дополнительных модулей. Spark SQL обеспечивает единый интерфейс загрузки и сохранения данных вне зависимости от источника данных и языка программирования.
Пример ниже демонстрирует, насколько легко можно загрузить данные из Avro и преобразовать их в Parquet.
val df = sqlContext.load("mydata.avro", "com.databricks.spark.avro")
df.save("mydata.parquet", "parquet")
Spark (включая Spark SQL и Spark Streaming) представляет собой единый фреймворк для решения аналитических задач, связанных как с пакетными, так и с потоковыми данными. Подобный инструмент в течение долгого времени был Святым Граалем в области обработки данных. Ранее существовали фреймворки, которые решали задачи лишь в одной плоскости. И хотя они обеспечивали хорошую масштабируемость, производительность и функциональность, о едином фреймворке все могли только мечтать, пока не появился Spark. Благодаря Spark один и тот же код (логика) может работать как с пакетными (RDD), так и с потоковыми (DStream) данными. DStream – это просто последовательность RDD. Такое представление стирает грань между пакетными и потоковыми нагрузками. Благодаря этому значительно сокращаются накладные расходы на обслуживание кода и обучение разработчиков, которые больше не должны осваивать два различных набора навыков.
Чтение из JDBC-источников данных
Spark SQL имеет встроенную поддержку чтения из JDBC-источников данных. Модуль позволяет извлекать данные из любых реляционных баз данных, поддерживающих JDBC, например, MySQL, PostgreSQL, H2 и др. Чтение данных из таких систем выполняется крайне просто и сводится к созданию виртуальной таблицы, ссылающейся на внешнюю таблицу. Затем данные из этой таблицы можно легко читать и соединять с другими источниками, поддерживаемыми Spark SQL.
Spark SQL и DataFrame
DataFrame – это распределенная коллекция данных, организованных посредством именованных столбцов. Данная абстракция предназначена для выборки, фильтрации, агрегации и визуализации структурированных данных. Ранее эта структура называлась SchemaRDD.
DataFrame API позволяет выполнять реляционные операции как с внешними источниками данных, так и со встроенными распределенными коллекциями Spark.
DataFrame поддерживает глубокую реляционную/процедурную интеграцию в рамках программ Spark и позволяет манипулировать данными как с помощью процедурного API Spark, так и посредством нового реляционного API, обеспечивающего более эффективную оптимизацию. DataFrame может быть создан непосредственно из RDD, что обеспечивает возможность реляционной обработки уже имеющихся данных.
DataFrame предоставляет более удобные и эффективные средства обработки данных, чем процедурный API Spark. В частности, можно вычислить несколько агрегаций за один проход с мощью SQL-инструкции, что достаточно сложно реализовать посредством традиционного процедурного API.
В отличие от RDD, DataFrame отслеживает свою схему и поддерживает различные реляционные операции, что обеспечивает более оптимизированное выполнение. DataFrame формирует схему посредством отражения (reflection).
DataFrame является «ленивой» структурой данных, то есть содержит логический план для вычисления набора данных, при этом вычисления не выполняются до тех пор, пока пользователь не запросит специальную «операцию вывода», например, сохранение. Такой подход обеспечивает эффективную оптимизацию всех операций.
Концепция DataFrame расширяет модель RDD. В результате, благодаря упрощенным методам фильтрации и агрегации, Spark-разработчики получают возможность быстрее и эффективнее работать с большими наборами структурированных данных. Для работы с DataFrame доступны API на Java, Scala и Python.
API Spark SQL для работы с источниками данных позволяет читать/записывать DataFrame из/в различных источников и форматов: Avro, Parquet, ORC, JSON, H2.
Пример, демонстрирующий краткость кода, которую обеспечивает DataFrame по сравнению с RDD:
Ниже представлены два эквивалентных фрагмента кода на Scala. В первом из них используется RDD API, а во втором – DataFrame API. Для примера рассмотрим набор данных, содержащий информацию о людях. Атрибутами каждого человека являются: имя, фамилия и возраст. Наша цель заключается в том, чтобы вычислить базовые статистические характеристики возраста людей, сгруппированных по имени.
case class People(firstname: String, lastname: String, age: Intger)
val people = rdd.map(p => (people.firstname, people.age)).cache()
// RDD Code
val minAgeByFN = people.reduceByKey( scala.math.min(_, _) )
val maxAgeByFN = people.reduceByKey( scala.math.max(_, _) )
val avgAgeByFN = people.mapValues(x => (x, 1))
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
val countByFN = people.mapValues(x => 1).reduceByKey(_ + _)
// Data Frame Code
df = people.toDF
people = df.groupBy("firstname").agg(
min("age"),
max("age"),
avg("age"),
count("*"))
Благодаря оптимизатору Catalyst, DataFrame позволяет получить значительное преимущество в скорости по сравнению с RDD. DataFrame поддерживает те же операции, что и реляционные языки, такие как SQL и Pig.
Подход к реализации аналитики реального времени с помощью Spark SQL
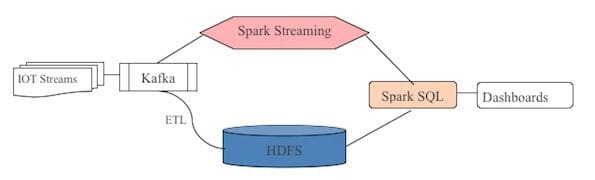
На рисунке ниже представлена логическая схема реализации аналитики реального времени с помощью Spark SQL. В основе данного подхода лежит лямбда-архитектура (lambda architecture), применяемая для создания аналитических систем реального времени в контексте больших потоковых данных.
Ограничения Spark SQL
Spark SQL имеет те же ограничения, что и любой другой инструмент, работающий в кластере Hadoop. Скорость обработки зависит не столько от скорости системы, сколько от количества пользователей, совместно использующих кластер.
Кроме того, при первом знакомстве код Spark SQL может показаться слишком лаконичным и непростым для понимания. Необходим некоторый опыт и практика, чтобы привыкнуть к стилю программирования и особенностям кода.
Заключение
Spark SQL – результат эволюционного развития базового API Spark. Базовый процедурный API Spark является достаточно общим и предоставляет лишь ограниченные возможности для автоматической оптимизации. Spark SQL существенно расширяет эти возможности.
По материалам: KDnuggets
1 комментарий
[…] https://datareview.info/article/analitika-v-rezhime-realnogo-vremeni-s-pomoshhyu-spark-sql/ […]