
Мы продолжаем список ключевых научных публикаций по глубокому обучению. В первой части мы рассмотрели 5 фундаментальных работ, сегодня расскажем еще о 4-х.
6. R-CNN (2013), Fast R-CNN (2015), Faster R-CNN (2015)
Некоторые специалисты считают, что публикация, представившая миру модель на основе регионов с СНС-признаками (РСНС, regions with CNN features, R-CNN), оказала большее влияние, чем любая из предыдущих работ, посвященных новым сетевым архитектурам. Данная работа, авторами которой являются Росс Гиршик (Ross Girshick) и его группа из Калифорнийского университета в Беркли, была процитирована более 1600 раз и представляет собой одно из выдающихся достижений в сфере компьютерного зрения. Две последующие работы, «Быстрая РСНС» («Fast R-CNN») и «Более быстрая РСНС» («Faster R-CNN»), как и следует из их названий, были направлены на то, чтобы ускорить выполнение модели и адаптировать ее для решения современных задач по обнаружению объектов (object detection).
Основным назначением РСНС является обнаружение объектов. Практически решение этой задачи сводится к выделению всех объектов на изображении ограничивающими рамками. Процесс можно разделить на два основных этапа: формирование гипотез о местоположении объектов или так называемое предложение регионов (region proposal) и классификацию.
Авторы отмечают, что можно использовать любой метод предложения регионов без информации о классе (class agnostic region proposal). В частности, они использовали метод селективного поиска (selective search). В процессе селективного поиска генерируется 2000 различных регионов, которые с наибольшей вероятностью содержат объект. После того, как предлагаемые регионы сгенерированы, они приводятся к размеру, пригодному для обработки с помощью обученной СНС (в данном случае применялась AlexNet), которая извлекает вектор признаков каждого региона. Далее вектор признаков подается на вход набору линейных классификаторов на основе метода опорных векторов (linear SVM), обученных для каждого класса, и выполняется классификация. Этот вектор также подается на вход регрессии для вычисления максимально точных координат ограничивающей рамки.
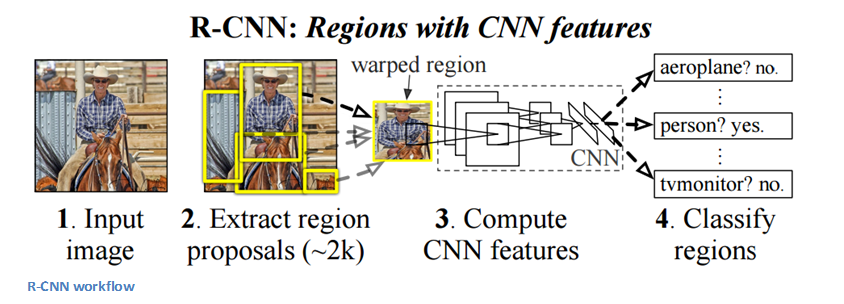
Рабочий процесс РСНС. 1. Входное изображение. 2. Формирование предлагаемых регионов (~2000). 3. Вычисление СНС-признаков. 4. Классификация регионов.
Далее выполняется алгоритм подавления немаксимумов (non-maximum suppression), который отклоняет регион, если он в значительной степени совпадает с другим регионом, имеющим более высокую оценку.
Быстрая РСНС
В следующей работе авторы модифицировали первоначальную РСНС, стремясь решить три основные проблемы: наличие нескольких этапов процесса (сверточная сеть, SVM, регрессия для вычисления координат ограничивающей рамки); слишком высокие требования к вычислительным ресурсам; слишком длительное выполнение (53 секунды на одно изображение). Оптимизированная модель, названная «Быстрой РСНС», обеспечила значительный выигрыш в скорости. Чтобы добиться такого результата, авторы применили следующие решения: совместное вычисление сверточных слоев для различных предложенных регионов и изменение очередности процесса генерации предлагаемых регионов и выполнения СНС. В этой модели изображение сначала проходит через СНС, признаки предлагаемых регионов мы получаем из последней карты признаков СНС (см. раздел 2.1 публикации), а затем выполняются полносвязные слои, а также регрессия и классификация.
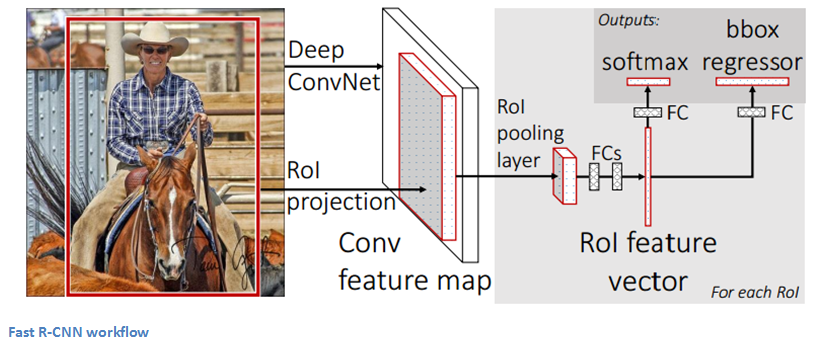
Рабочий процесс Быстрой РСНС.
Более быстрая РСНС
Поскольку рабочий процесс как РСНС, так и Быстрой РСНС был достаточно сложным, в своей третьей публикации авторы представили еще более оптимизированную модель, которая была названа «Более быстрой РСНС». Авторы разработали специальную сеть для предложения регионов (region proposal network, RPN) и поместили ее после последнего сверточного слоя. Эта сеть позволяет генерировать предлагаемые регионы на основе лишь последней сверточной карты признаков. После этого этапа используется стандартная схема (пулинг целевого региона (RoI pooling), полносвязные слои, а затем классификация и регрессия).
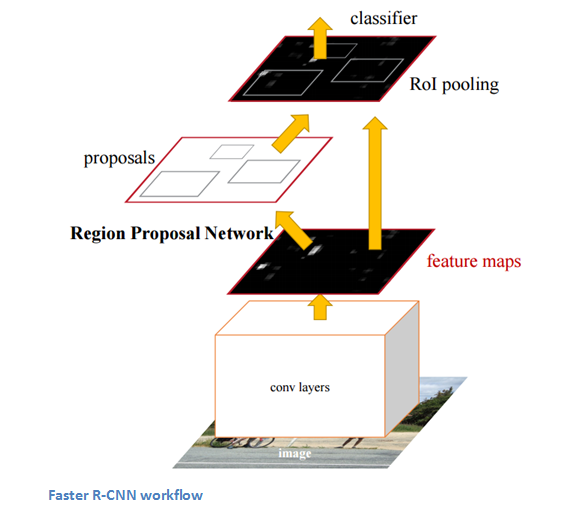
Рабочий процесс Более быстрой РСНС.
Значение публикаций
Возможность определить, что данный объект находится на изображении, – это уже достижение, но способность определить точное положение объекта на изображении – это большой прорыв для компьютерной системы. Последняя версия РСНС на сегодняшний день является стандартом для программ по обнаружению объектов.
7. Generative Adversarial Networks (2014)
Генеративные соревновательные сети (generative adversarial network), по мнению Яна Лекуна, могут стать следующим большим прорывом. Прежде чем обсудить публикацию, давайте поговорим о соревновательных примерах (adversarial example). Рассмотрим обученную СНС, демонстрирующую хорошие результаты на данных ImageNet. Возьмем некоторое изображение и слегка модифицируем его таким образом, чтобы максимизировать ошибку сети. Мы стремимся к тому, чтобы предсказанный сетью класс изменился, но с точки зрения человека модификации изображения не были заметны. Таким образом, соревновательные примеры – это изображения, которые обманывают сверточную сеть.

Изображения в крайнем левом столбце – правильно классифицированные примеры. В среднем столбце представлена разница между левым и правым изображением. Изображения в крайнем правом столбце сеть классифицирует, как принадлежащие к классу «страус»! Несмотря на то, что разница между левым и правым изображением незаметна для человека, сверточная сеть допускает радикальные ошибки при классификации.
Соревновательные примеры (представлены в данной публикации) впечатлили многих специалистов и быстро стали популярной темой для исследований. Теперь давайте поговорим непосредственно о генеративных соревновательных сетях. Рассмотрим две модели: генеративную (generative) и дискриминативную (discriminative). Задача дискриминативной модели заключается в том, чтобы определить, является ли данное изображение естественным (взятым из набора данных) или искусственно созданным. Задача генеративной модели состоит в создании таких изображений, чтобы с их помощью дискриминативная модель обучилась давать правильные ответы. Эту концепцию можно рассматривать, как игру двух лиц с нулевой суммой (zero-sum two player game), где применяется правило минимакса (minimax). Авторы публикации используют следующую аналогию: генеративная модель – это «команда фальшивомонетчиков, старающихся создать и использовать фальшивые купюры», а дискриминативная модель – это «полиция, стремящаяся обнаружить фальшивые купюры». Генератор пытается «обмануть» дискриминатор, в то время как дискриминатор старается не поддаться на обман. По мере обучения, обе модели совершенствуются до того состояния, когда «подделку уже невозможно отличить от подлинного образца».
Значение публикации
Интересная идея, но в чем заключаются ее преимущества? Как пишет Ян Лекун в своей статье на Quora, при таком подходе дискриминатор «знает» «внутреннее представление данных», поскольку его обучение было направлено на то, чтобы понимать понимать ()о направлено на то чтобыы ()атор старается ()о разницу между естественными изображениями из набора данных и искусственно созданными изображениями. Следовательно, его можно использовать для извлечения признаков в СНС. Кроме того, мы можем создавать классные искусственные изображения, которые, на мой взгляд, выглядят очень естественно.
8. Генерация описаний для изображений (2014)
Что будет, если объединить сверточную нейронную сеть с рекуррентной нейронной сетью (РНС, recurrent neural network, RNN)? В результате мы получим удивительное приложение. В данной публикации, авторами которой являются Андрей Карпаты и Фей-Фей Ли (Fei-Fei Li), рассматривается комбинация сверточной сети и двунаправленной (bidirectional) рекуррентной сети, позволяющая генерировать описания на естественном языке для различных регионов изображения. Модель принимает на входе изображение, а на выходе мы получаем следующий результат:

Результат работы модели.
Это просто невероятно. Давайте сравним эту модель с обычной СНС. В контексте традиционных СНС каждое изображение из обучающего набора данных имеет одну конкретную одна конкретная () имеем ()ычной СНС.уррентной сети, позвометку класса. В отличие от этого, модель, представленная в данной публикации, обучается на изображениях, имеющих текстовые описания. Такие метки называются слабыми метками (weak label), то есть фрагменты описания соответствуют неизвестным регионам изображения. Обучаясь на этих данных, одна модель «находит скрытое соответствие между фрагментами описания и регионами изображения, к которым они относятся». Другая модель принимает на входе изображение и генерирует текстовое описание. Давайте подробнее рассмотрим два этих компонента: модель для поиска соответствия (alignment model) и модель для генерации описания (generation model).
Модель для поиска соответствия
Задача этой модели заключается в том, чтобы иметь возможность сопоставлять графическую и текстовую информацию (изображение и описание). Модель принимает на входе изображение и описание, а на выходе мы получаем оценку их соответствия. (Карпаты ссылается на публикацию, описывающую подробности процесса. Обучение выполняется на совместимых и несовместимых парах изображение-описание.)
Теперь давайте рассмотрим представление изображения. На первом шаге изображение обрабатывается с помощью РСНС, чтобы обнаружить отдельные объекты. РСНС обучена на данных ImageNet. Лучшие 19 регионов с объектами (плюс исходное изображение) преобразуются к представлению в 500-мерном пространстве. Мы получили 20 различных 500-мерных векторов для каждого изображения. Таким образом, у нас уже есть информация об изображении, и теперь нам нужна информация об описании. Мы преобразуем слова к представлению в том же многомерном пространстве. Это реализуется с помощью двунаправленной рекуррентной сети. В итоге мы получаем информацию о контексте слов в данном описании. Поскольку информация об изображении и описании представлена в одном пространстве, мы можем оценить их соответствие с помощью скалярного произведения.
Модель для генерации описания
Основная задача модели для поиска соответствия – это создании набора данных, содержащего набор регионов изображений (полученных с помощью РСНС) и соответствующий текст (полученный с помощью РНС). Теперь модель для генерации описания должна обучиться на этом наборе данных, чтобы получить возможность генерировать описания для изображений. Модель принимает на входе изображение и пропускает его через СНС. Софтмакс-слой не применяется, поскольку выходы полносвязного слоя становятся входами рекуррентной сети. Напомним, что назначение рекуррентной сети заключается в формировании распределений вероятностей для различных слов в предложении. (Рекуррентные сети обучаются аналогично сверточным сетям.)
Эта публикация определенно является одной из самых интересных и сложных среди рассмотренных нами работ. Поэтому, если у вас есть какие-либо замечания или дополнительные пояснения, пожалуйста, напишите их в комментариях!

Рабочий процесс модели для поиска соответствия и модели для генерации описания.
Значение публикации
В данной работе была реализована очень интересная концепция, объединяющая в себе сверточную и рекуррентную сеть. В результате авторы создали впечатляющее и очень полезное приложение, в котором воплотились концепции компьютерного зрения и обработки естественного языка. Данная работа открывает новые пути решения задач, лежащих на пересечении различных областей знаний.
9. Spatial Transformer Networks (2015)
Давайте рассмотрим еще одну из последних работ в области компьютерного зрения. Эта публикация была выпущена группой исследователей из лаборатории Google Deepmind немногим более года назад. В данной работе был представлен модуль, названный пространственным преобразователем (spatial transformer). Функция этого модуля заключается в том, что он преобразует изображение таким образом, чтобы последующим слоям нейронной сети было легче его классифицировать. То есть, вместо того, чтобы модифицировать общую архитектуру СНС, авторы предлагают изменять само изображение, перед тем, как подавать его на вход данного сверточного слоя. Модуль выполняет две основные операции: нормализацию положения (если объект повернут в пространстве или имеет неподходящий масштаб) и акцентирование пространственного внимания (направляет внимание на нужный объект). В случае традиционной СНС, если мы хотим, чтобы наша модель хорошо справлялась с изображениями, где объекты могут иметь различный масштаб и различную ориентацию в пространстве, нам потребуется очень много обучающих примеров. Давайте разберемся, как пространственный преобразователь помогает справиться с этой проблемой.
Чтобы добиться пространственной инвариантности, в традиционных СНС применяется пулинг по максимуму. Интуитивное обоснование для этого подхода заключается в том, что когда мы знаем, что данный признак присутствует во входных данных, абсолютное положение этого признака имеет не такое большое значение, как его положение относительно других признаков. Предложенный авторами публикации метод пространственного преобразования является динамическим, то есть выполняет различные преобразования для каждого входного изображения. Этот метод намного сложнее, чем простой и предопределенный пулинг. Давайте рассмотрим, как работает пространственный преобразователь. В состав модуля входят следующие компоненты:
-
Локализующая сеть (localization network). Принимает входную карту признаков и вычисляет параметры пространственного преобразования, которое необходимо применить. Параметры (тета) могут быть 6-мерными для аффинного преобразования.
-
Генератор семплирующей сетки (sampling grid generator). Исходная пространственная сетка (regular grid) с помощью аффинного преобразования (тета) преобразуется в семплирующую сетку (sampling grid).
-
Семплер (sampler). Преобразует входную карту признаков с помощью семплирующей сетки.
Пространственный преобразователь.
Пространственный преобразователь может быть внедрен на любом участке СНС. Он позволяет сети обучиться тому, как преобразовывать карты признаков, чтобы минимизировать целевую функцию в процессе обучения.
Результат применения пространственного преобразователя в качестве первого слоя полносвязной сети, обученной для классификации искаженных цифр из набора MNIST. (a) На вход пространственного преобразователя подается изображение цифры из набора MNIST, искаженное посредством случайного смещения, масштабирования, вращения и добавления шума. (b) Локализующая сеть, входящая в состав пространственного преобразователя, предсказывает преобразование, которое необходимо применить к входному изображению. (c) Выход пространственного преобразователя после выполнения преобразования. (d) Результат классификации, выполненной следующей далее полносвязной сетью на основе выхода пространственного преобразователя. В процессе обучения сверточной сети с пространственным преобразователем используются только метки классов, то есть система не получает никаких знаний об истинных преобразованиях.
Значение публикации
Данная публикация хорошо демонстрирует тот факт, что усовершенствования СНС необязательно должны быть основаны на существенных изменениях в сетевой архитектуре. Добиться улучшения результатов можно и не изобретая новую ResNet или модуль Inception. В данной работе реализована простая идея применения аффинного преобразования к входному изображению, что позволяет сделать модель более устойчивой к смещению, масштабированию и вращению изображений. Если вас интересует дополнительная информация, взгляните на видео от Deepmind, где представлена отличная анимация результатов применения пространственного преобразователя в СНС, а также обратите внимание на обсуждение на Quora.
На этом заканчивается наш обзор важнейших публикаций в области глубоких сверточных сетей. Если мы что-то упустили, пожалуйста, напишите в комментариях! Если вы хотите подробнее изучить данную тему, рекомендуем вам курс Стэнфордского университета CS231n, видео-лекции которого (на английском языке) легко можно найти на YouTube.
Перевод Станислава Петренко