
Глубокое обучение – горячая тема для исследований. Перед вами подборка рекомендаций и объяснение тонкостей обучения глубоких сетей.
Глубокие нейронные сети (deep neural network), в частности сверточные нейронные сети (convolutional neural network), позволяют создавать модели, состоящие из множества слоев, которые способны обучаться представлениям данных с различными уровнями абстракции. Благодаря таким моделям, удалось достичь невероятных результатов в задачах визуального распознавания объектов, обнаружения объектов, распознавания текста и во многих других областях, таких как разработка лекарственных препаратов и геномика.

В последнее время было опубликовано большое количество серьезных работ по теме, а также появились качественные программные пакеты с открытым исходным кодом для реализации сверточных сетей. Кроме того, появилось много хороших руководств и документации. Однако среди множества материалов отсутствует актуальное подробное руководство, описывающее, как создать хорошую глубокую сверточную сеть с нуля. Поэтому в данной статье мы собрали и описали многие важные детали и тонкости реализации глубоких сверточных сетей.
Введение
Мы предполагаем, что вы уже обладаете базовыми знаниями по глубокому обучению, поэтому сразу перейдем к деталям реализации глубоких сетей для задач обработки изображений. Мы затронем восемь аспектов:
- Аугментация данных.
- Предобработка данных.
- Инициализация.
- Процесс обучения.
- Выбор функций активации.
- Регуляризация.
- Визуализация.
- Ансамбли глубоких сетей.
Слайды к данной статье доступны по следующей ссылке.
1. Аугментация данных
Аугментация данных (data augmentation) – это методика создания дополнительных обучающих данных из имеющихся данных. Для достижения хороших результатов глубокие сети должны обучаться на очень большом объеме данных. Следовательно, если исходный обучающий набор содержит ограниченное количество изображений, необходимо выполнить аугментацию, чтобы улучшить результаты модели.
Существует множество вариантов аугментации. Самыми популярными являются следующие: отражение по горизонтали (horizontal flip), случайное кадрирование (random crop) и изменение цвета (color jitter). Можно применять различные комбинации, например, одновременно выполнять поворот и случайное масштабирование. Кроме того, можно варьировать величину насыщенности (saturation) и значения (value) всех пикселей (компоненты S и V цветового пространства HSV). В частности, можно возвести эти компоненты в степень из интервала от 0,25 до 4, умножить их на коэффициент из интервала от 0,7 до 1,4, или прибавить к ним величину из интервала от –0,1 до 0,1. Также можно прибавить величину из интервала от –0,1 до 0,1 к величине тона (hue) всех пикселей (компонента H цветового пространства HSV). Аналогичные преобразования можно применить к фрагментам изображений.
В 2012 году в работе [Krizhevsky et al.] при обучении знаменитой сети Alex-Net был использован специальный вариант метода главных компонент (principal component analysis, PCA). Суть подхода заключается в изменении интенсивности RGB-каналов обучающих изображений. Вначале к RGB-значениям пикселей всех обучающих изображений применяется PCA. Затем в пределах каждого изображения к RGB-значению каждого пикселя (Ixy = [IxyR, IxyG, IxyB]T) прибавляется следующая величина:
[p1, p2, p3][α1λ1, α2λ2, α3λ3]T,
где pi и λi представляют собой соответственно i-й собственный вектор (eigenvector) и i-е собственное значение (eigenvalue) ковариационной матрицы RGB-значений пикселей размерности 3 × 3, а αi является случайной величиной из нормального распределения с математическим ожиданием 0 и среднеквадратическим отклонением 0,1. Обратите внимание, каждое значение αi генерируется один раз для всех пикселей данного обучающего изображения. Когда модель снова встретит данное обучающее изображение, она сгенерирует другое случайное значение αi с целью аугментации данных.
Авторы публикации утверждают, что благодаря данному подходу, модель получает возможность идентифицировать объекты независимо от яркости и цвета освещения. В рамках соревнования ImageNet 2012 данный метод аугментации позволил уменьшить ошибку более чем на 1%.
2. Предобработка данных
Итак, мы получили большое количество обучающих изображений. Теперь необходимо выполнить их предобработку. Далее мы рассмотрим несколько вариантов этой процедуры.
Одним из наиболее распространенных методов предобработки является центрирование данных к нулю (zero-centering) и последующая нормализация (normalization). Для этого понадобится две строки кода на Python:
>>> X -= np.mean(X, axis = 0) # zero-center >>> X /= np.std(X, axis = 0) # normalize
где X представляет собой массив входных данных (количество элементов × количество измерений). Другая форма этой предобработки нормализует каждое измерение таким образом, чтобы минимальное и максимальное значение по данному измерению были равны –1 и 1 соответственно. Данную предобработку имеет смысл применять только в том случае, когда есть основания полагать, что различные входные признаки имеют различный масштаб (или единицы измерения), но при этом обладают примерно одинаковой ценностью для модели. В случае изображений, относительные масштабы пикселей исходно примерно одинаковы (и находятся в интервале от 0 до 255), поэтому нет строгой необходимости выполнять данную предобработку.
Другой метод предобработки, аналогичный первому, называется PCA отбеливание (PCA whitening). Данные сначала центрируются, как описано выше, а затем вычисляется ковариационная матрица, описывающая структуру корреляций в данных:
>>> X -= np.mean(X, axis = 0) # zero-center >>> cov = np.dot(X.T, X) / X.shape[0] # compute the covariance matrix
Далее мы выполняем декорреляцию, проецируя исходные данные (центрированные) на собственный базис (eigenbasis):
>>> U,S,V = np.linalg.svd(cov) # compute the SVD factorization of the data covariance matrix >>> Xrot = np.dot(X, U) # decorrelate the data
Последним этапом является отбеливание. Мы берем данные в собственном базисе и делим каждое измерение на собственное значение, чтобы нормализовать масштаб:
>>> Xwhite = Xrot / np.sqrt(S + 1e-5) # divide by the eigenvalues (which are square roots of the singular values)
Обратите внимание, мы прибавляем малую константу 1e–5, чтобы предотвратить деление на ноль. Недостатком этого преобразования является то, что в его результате может быть значительно усилен шум в данных. Это связано с тем, что данный метод преобразует все измерения к одинаковому размеру, в том числе, измерения, обладающие малой дисперсией и являющиеся в своем большинстве шумом. На практике этот недостаток можно нивелировать с помощью более сильного сглаживания (т.е. увеличив значение малой константы).
Для полноты мы рассмотрели несколько методов предобработки. Следует отметить, что в случае сверточных сетей последний метод не применяется, в то время как центрирование данных является необходимым. Кроме того, часто выполняется нормализация каждого пикселя.
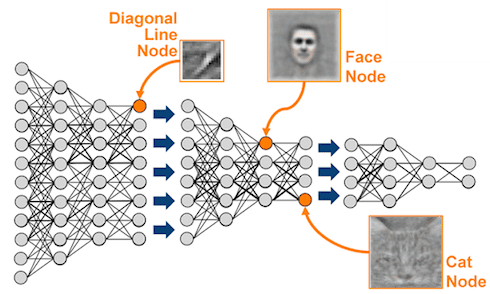 3. Инициализация
3. Инициализация
Данные готовы, но прежде чем начать обучение сети, необходимо инициализировать ее параметры.
Инициализация нулями
В идеальном случае при правильной нормализации данных логично предположить, что примерно половина весов будет иметь положительные значения, а другая половина – отрицательные. Далее нам может показаться, что рационально будет задать все исходные веса равными нулю. Однако это суждение ошибочно. В этом случае все нейроны вычислят одинаковые выходы, следовательно, далее они также вычислят одинаковые градиенты в процессе обратного распространения ошибки и, соответственно, обновление параметров также будет одинаковым. Другими словами, если веса всех нейронов исходно будут одинаковыми, у нас не будет необходимого источника асимметрии между нейронами.
Инициализация малыми случайными значениями
Таким образом, нам нужно, чтобы веса были близки к нулю, но не равны ему. Для этого мы можем инициализировать их малыми случайными значениями очень близкими к нулю, что позволит нарушить симметрию. В результате, все исходные веса будут случайными и уникальными, следовательно, обновляться они будут по-разному, что нам и нужно. Вычислить веса можно следующим образом:
weights ~ 0,001 × N(0, 1)
где N(0, 1) – нормальное распределение с математическим ожиданием, равным 0, и среднеквадратическим отклонением, равным 1. Кроме того, можно использовать малые случайные значения из равномерного распределения, но на практике этот подход не оказывает существенного влияния на результат.
Калибровка дисперсии
Проблема описанного выше подхода заключается в том, что дисперсия распределения выхода нейрона, инициализированного случайным образом, возрастает с увеличением количества входов. Мы можем нормализовать дисперсию выхода каждого нейрона, разделив вектор весов на квадратный корень из количества входов:
>>> w = np.random.randn(n) / sqrt(n) # calibrating the variances with 1/sqrt(n)
где функция randn() генерирует случайные числа из упомянутого выше нормального распределения, а n является количеством входов. Благодаря этому подходу, все нейроны сети исходно имеют приблизительно одинаковое выходное распределение, что позволяет повысить скорость сходимости. Подробный вывод этой формулы можно найти на страницах 18 – 23 слайдов. Обратите внимание, в выводе формулы не учитывается влияние ReLU-нейронов.
Актуальная рекомендация
Как уже было сказано, предыдущий метод инициализации с применением калибровки дисперсии не учитывает влияние ReLU-нейронов. В одной из недавних работ [He et al.] была выведена формула инициализации, предназначенная специально для ReLU-нейронов:
>>> w = np.random.randn(n) * sqrt(2.0/n) # current recommendation
На практике рекомендуется применять именно эту формулу.
4. Процесс обучения
Итак, все готово. Приступим к обучению глубоких сетей!
Фильтры и размер объединения (pooling size)
Желательно, чтобы размер входных изображений представлял собой степень двойки, например, 32 (CIFAR-10), 64, 224 (ImageNet), 384, 512 и т.д. Кроме того, важно применять малый фильтр (например, 3 × 3) и малый шаг (stride) (например, 1) с заполнением нулями (zero-padding), что позволяет не только уменьшить количество параметров, но и повысить точность сети в целом. Частный случай, упомянутый выше (фильтр 3 × 3 с шагом 1), позволяет сохранить пространственный размер карт признаков и изображений. Рекомендуемый размер объединения составляет 2 × 2.
Скорость обучения (learning rate)
Илья Сатскевер (Ilya Sutskever) рекомендует делить градиенты на размер мини-пакета. Благодаря этому, не приходится изменять скорость обучения при каждом изменении размера мини-пакета. Подходящую скорость обучения можно определить с помощью валидационного набора данных. Исходно скорость обучения обычно выбирается равной 0,1. Далее, если мы не наблюдаем прогресс на валидационном наборе, необходимо разделить скорость обучения на 2 (или на 5) и продолжить. Результат может превзойти ожидания.
Тонкая настройка предварительно обученных моделей
В настоящее время многие исследовательские группы открывают публичный доступ к своим предварительно обученным глубоким сетям (например, Caffe Model Zoo, VGG Group). Благодаря удивительной обобщающей способности этих моделей, мы можем непосредственно применять их в своих приложениях. Чтобы еще лучше адаптировать предобученную модель к новым данным, можно выполнить несложную тонкую настройку. Как показано в таблице ниже, двумя ключевыми факторами являются: размер нового набора данных (малый или большой) и сходство нового набора данных с исходным набором данных, который использовался для обучения. В разных ситуациях применяются различные стратегии тонкой настройки.
- Наборы данных похожи, новых данных много. Необходимо обучить на новых данных несколько верхних слоев предобученной модели с малой скоростью обучения.
- Наборы данных похожи, новых данных мало. Необходимо обучить линейный классификатор на признаках, извлеченных из верхних слоев предобученной модели.
- Наборы данных не похожи, новых данных много. Необходимо обучить на новых данных большое количество слоев предобученной модели с малой скоростью обучения.
- Наборы данных не похожи, новых данных мало. Это сложная ситуация. Поскольку данных мало, рационально использовать линейный классификатор. При этом, поскольку данные различны, не следует обучать классификатор на верхних слоях, которые содержат специфичные для набора данных признаки. Вместо этого лучше обучить классификатор (например, SVM) на признаках (активациях) из более ранних слоев.
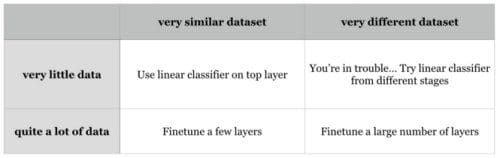
Для примера отметим, что такие наборы данных, как Caltech-101 и ImageNet, похожи между собой, потому что ориентированы на объекты. С другой стороны, набор данных Places Database отличается от вышеназванных, поскольку ориентирован на сцены.
Во второй части статьи мы рассмотрим оставшиеся четыре аспекта реализации глубоких сетей.
По материалам: KDnuggents
Перевод Станислава Петренко