
2017 год обещает принести дата-сообществу множество новых возможностей, а также несколько непростых проблем. Бен Лорика (Ben Lorica) представляет свой взгляд в недалекое будущее.
1. Все больше data scientist’ов будут применять глубокое обучение

В 2016 году мы стали свидетелями значительных успехов, достигнутых в области глубокого обучения. Были выпущены новые инструменты, существенно облегчающие реализацию глубокого обучения, а также обеспечивающие прямую интеграцию с существующими платформами и фреймворками для работы с большими данными.
В 2017 году большинство data scientist’ов так или иначе будут работать с глубоким обучением, поскольку эта технология позволяет решать очень широкий круг задач, многие из которых становятся критически важными. В числе таких задач можно назвать анализ временных рядов и событий (включая обнаружение аномалий), Интернет вещей, анализ данных от сенсоров, распознавание речи, интеллектуальный анализ текста и многие другие.
2. Возрастет спрос на навыки в области инженерии данных

В 2012 году журнал «Harvard Business Review» назвал профессию data scientist «самой сексуальной профессией 21 века». Ожидается, что в 2017 году такие специалисты будут по-прежнему широко востребованы, однако спрос сместится в сторону навыков, свойственных data engineer’ам. Компании ищут data scientist’ов, способных хорошо программировать и взаимодействовать с производственными системами. Да, действительно, это уникальная комбинация навыков, однако сумма зарплаты такого специалиста будет тоже уникальной.
3. Большее количество компаний будут использовать облачные сервисы

Недавнее исследование, проведенное компанией O’Reilly, показало, что «после того, как компания приобретает некоторый опыт работы с большими данными в облаке, возрастает вероятность того, что данная компания расширит использование подобных облачных сервисов. Другими словами, тот, кто попробовал воду, вероятнее прыгнет в бассейн».
В настоящее время компании имеют доступ к широкому спектру облачных сервисов для хранения и обработки данных, визуализации, аналитики и реализации искусственного интеллекта. В данной области широко применяются компоненты с открытым исходным кодом, однако выяснилось, что проприетарные сервисы также пользуются значительным спросом.
Поскольку управление облаком и доступными в нем инструментами ложится на плечи поставщика облачных услуг, аналитики могут сосредоточиться непосредственно на решении задач, а не на настройке инструментов. При этом, безусловно, необходимо научиться проектировать и реализовывать приложения, которые будут работать в облаке.
4. И все же облачные сервисы не смогут полностью заменить другие подходы к хранению и обработке данных

Такие факторы, как необходимость работы с конфиденциальными данными, вопросы безопасности и приватности, требуют применения комбинированного подхода, в рамках которого используются облачные, локальные и гибридные приложения. Кроме того, будут применяться приложения, использующие услуги специализированных провайдеров облачных услуг, таких как Predix для промышленного Интернета вещей или облако ЦРУ, созданное компанией Amazon Web Services. Компаниям потребуются специалисты для проектирования систем, способные воспользоваться преимуществами каждого из подходов.
5. Новые инструменты упростят решение многих задач

Новые аналитические инструменты уже существенно облегчили множество задач по анализу данных. Некоторые из них не требуют программирования, другие облегчают интеграцию кода, визуализаций и текста в один рабочий процесс. Благодаря таким инструментам, пользователи, не являющиеся статистиками или аналитиками, могут самостоятельно выполнять рутинные задачи по анализу данных, что позволяет экспертам сконцентрироваться на более сложных проектах или на оптимизации приложений и архитектуры в целом.
«Демократизация» аналитики происходит уже в течение нескольких лет, однако в дополнение к этому в последнее время появились инструменты, облегчающие выполнение более серьезных аналитических задач (например, Microsoft Azure), упрощающие прием крупномасштабных потоковых данных и реализацию сложного машинного обучения (например, Google Cloud Platform и Amazon Machine Learning).
6. Ускорится процесс отделения вычислений от хранилища
В прошлом ноябре завершился проект AMPLab Калифорнийского университета в Беркли. Команда проекта, в активе которой разработка Apache Spark и Alluxio, является далеко не единственной группой специалистов, особо отмечающих необходимость отделения вычислений от хранилища. Популярные облачные объектные хранилища и даже некоторые новые архитектуры глубокого обучения делают акцент на этом подходе.
7. Продолжится развитие «блокнотов» и средств для организации рабочего процесса
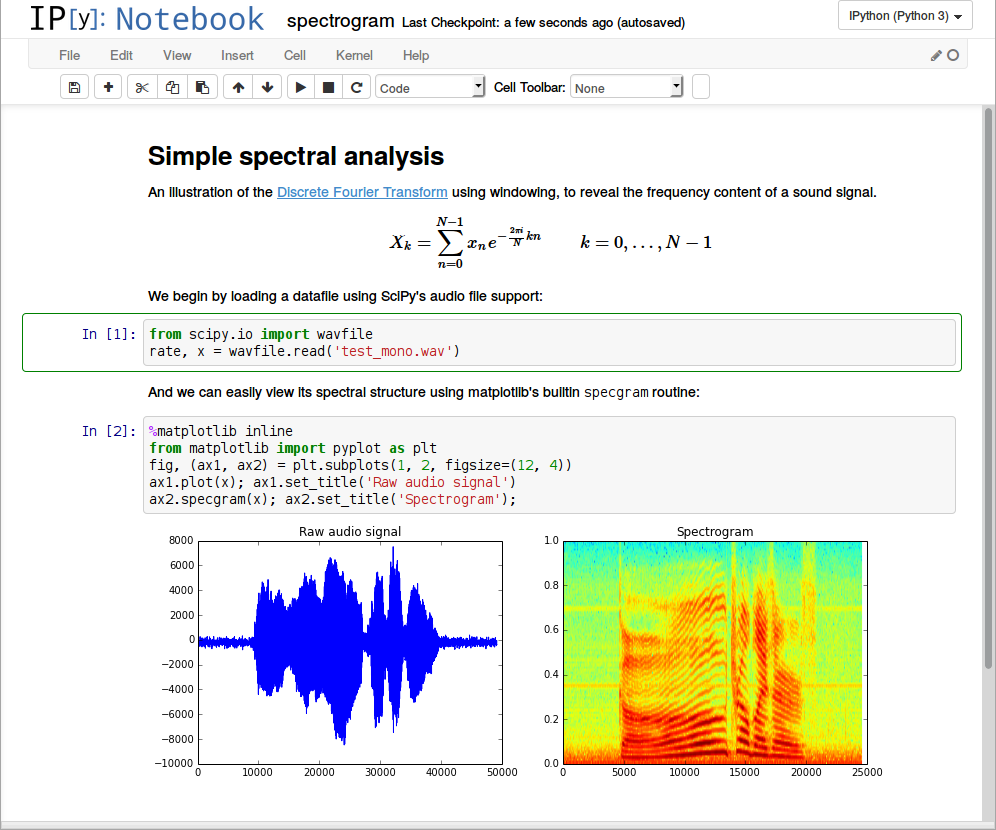
Инструмент Jupyter Notebook широко используется data scientist’ами, поскольку предоставляет богатую архитектуру элементов для решения широкого спектра задач, таких как очистка и преобразование данных, численное моделирования, статистическое моделирование, машинное бучение и др. (Например, интерактивные учебники O’Reilly реализованы на основе Jupyter Notebook.) Этот инструмент крайне полезен для команд, работающих над одним проектом, поскольку позволяет создавать и распространять документы, объединяющие в себе «живой» код, уравнения, визуализации и поясняющий текст. Кроме того, подключив Jupyter к Spark, можно писать Python-код для Spark, используя простой и удобный интерфейс, вместо командной строки Linux или оболочки Spark.
Data scientist’ам требуются разнообразные инструменты. Beaker Notebook поддерживает множество языков программирования. В настоящее время также доступно большое количество подобных инструментов, разработанных для Spark-сообщества (Spark Notebook, Apache Zeppelin и Databricks Cloud). Однако не все специалисты используют эти средства, поскольку они не предназначены для управления сложными процессами обработки данных. Для этого лучше подходят специализированные инструменты для организации рабочих процессов. Data engineer’ы предпочитают инструменты, используемые разработчиками программного обеспечения. Учитывая широкое внедрение глубокого обучения и других новых технологий, логично предположить, что существующие инструменты будут развиваться еще более активно.
8. Дата-сообщество продолжит вырабатывать стандарты, регулирующие аспекты приватности и этики

В то время, когда машинное обучение становится все более распространенным, источники данных более разнообразными, а алгоритмы более сложными, становится все труднее добиться прозрачности. Задача обеспечения объективности приложений, работающих с данными, сложна и актуальна, как никогда ранее. В 2017 году ожидается активное обсуждение государственной политики, регулирующей данные аспекты. Мы также предвидим активную разработку подходов, направленных на выявление предвзятости, а также все большее осознание того факта, что предвзятые допущения приводят к предвзятым результатам.
По материалам O’Reilly