
Разве сложно вычислить коэффициент конверсии (conversion rate)? Берем количество пользователей, выполнивших целевое действие, и делим на общее количество пользователей. Готово. Все просто, но только не в том случае, когда имеет место существенная временная задержка.
Введение
Окончив школу, я присоединился к Spotify в качестве первого специалиста по анализу данных. Один из моих первых проектов был направлен на понимание коэффициента конверсии. Коэффициент конверсии в отношении перехода пользователей от бесплатного доступа к платному вычислить очень непросто, поскольку здесь мы имеем дело с большой временной задержкой. В то время записывающие компании сомневались в том, что мы сможем конвертировать большое количество пользователей, и этот вопрос был постоянным источником разногласий. Действительно, на платный доступ перешла лишь небольшая часть наших пользователей, в то время как количество пользователей с бесплатным доступом возрастало большими темпами. Коэффициент конверсии оставался неизменным, если не уменьшался.
Объяснение этого явления было найдено, когда я разделил пользователей на когорты. Например, берем всех пользователей, зарегистрировавшихся 1 мая, и отслеживаем их коэффициент конверсии с течением времени. Этот подход дал отличный результат: мы увидели, что коэффициент конверсии постоянно возрастает. В течение нескольких первых лет конверсия возрастала почти равномерно. Это было потрясающе. Некоторые «старые» когорты, к которым относились пользователи, зарегистрировавшиеся более 2 лет назад, имели сумасшедшие уровни конверсии около 40-50%. Этот подход показал, что конверсия не была проблемой. Все дело было в том, что количество наших пользователей увеличивалось экспоненциально, и поэтому текущий коэффициент конверсии был «искусственно» низким.
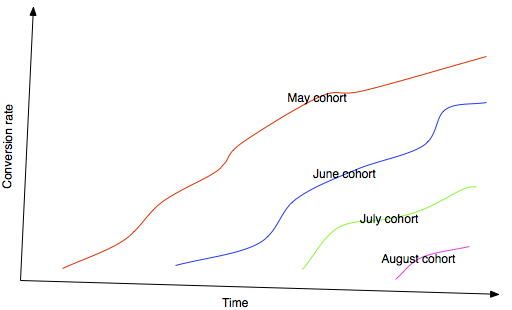
Вывод заключается в том, что в некоторых случаях коэффициент конверсии невозможно выразить в виде одного числа. Иногда этот единый показатель является полезной метрикой, но во многих случаях это не так. Единый коэффициент конверсии в отношении Spotify не слишком полезен сам по себе, поскольку пользовательская база не находится в равновесии. Пока пользовательская база растет и пока существует значительная временная задержка конверсии, мы никак не можем охарактеризовать ее одним числом.
Пример. Коэффициент конверсии для стартапов 2008-2015
Давайте рассмотрим все неправильные подходы к вычислению коэффициента конверсии, и в итоге придем к правильному. Ради интереса я извлек приличный объем данных о стартапах из известной онлайн базы. Не будем вдаваться в детали сбора данных, скажу лишь, что это весело, но если слишком увлечься, ваш клиент может быть заблокирован. Вероятно, я мог бы использовать какой-нибудь другой старый и скучный набор данных, но, как известно, анализ на 38.1% более интересен, если аналитик имеет отношение к данным.
Итак, в нашем наборе данных 1836 компаний, привлекших инвестиции, 243 (13%) из которых «конвертировались» (exit), то есть либо вышли на биржу (IPO), либо были приобретены. Теперь давайте спросим себя, какова динамика коэффициента конверсии? Больше ли этот коэффициент для новых компаний? Или со временем становится все труднее конвертировать компанию? Наивный подход состоит в том, чтобы разбить компании на группы по году основания и вычислить коэффициенты конверсии:
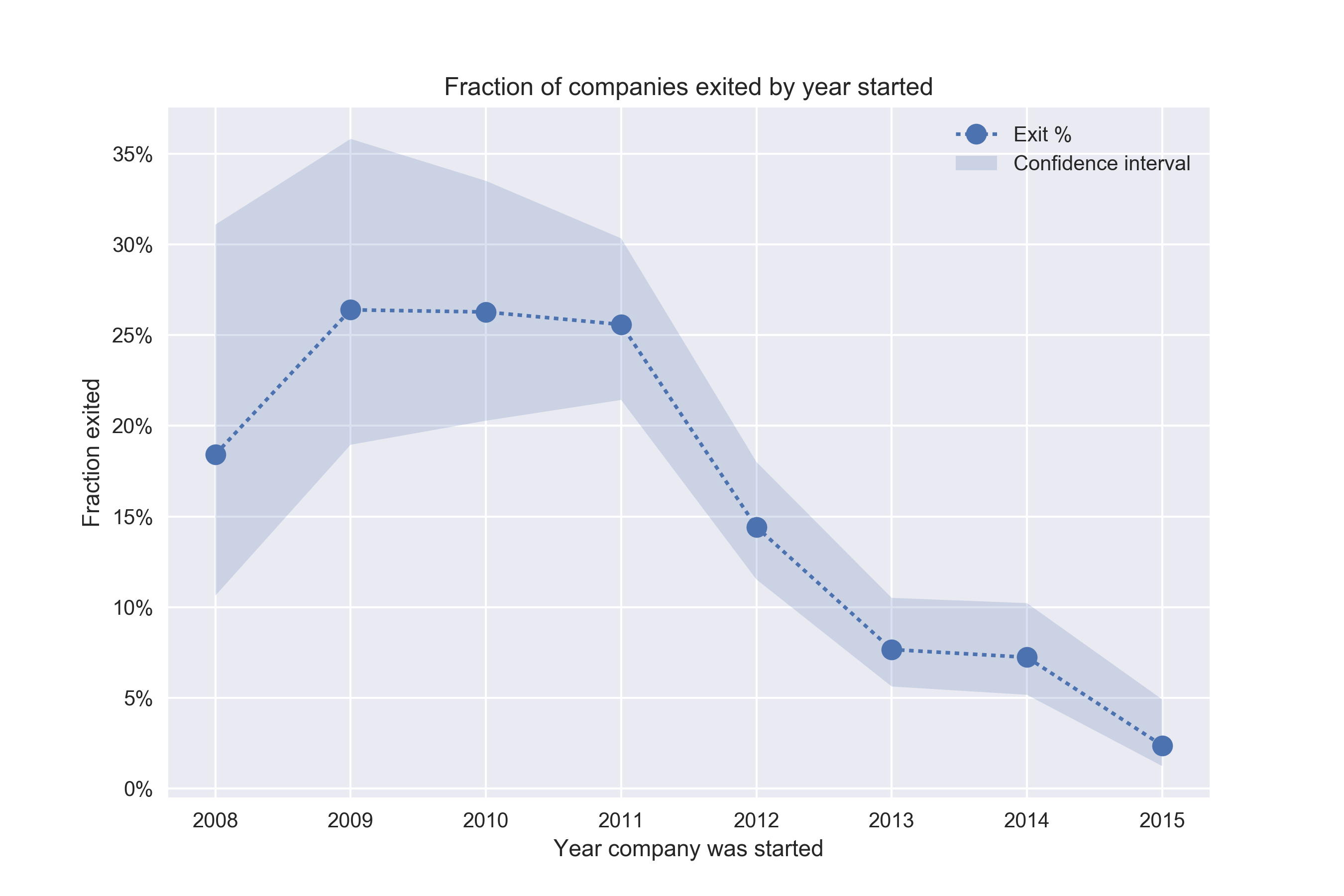
Похоже, что за исключением 2008 года, коэффициент конверсии уменьшается. Почему? Действительно ли со временем становится все труднее и труднее конвертировать компанию?
Теперь давайте посмотрим на время, прошедшее с момента основания до момента конверсии:
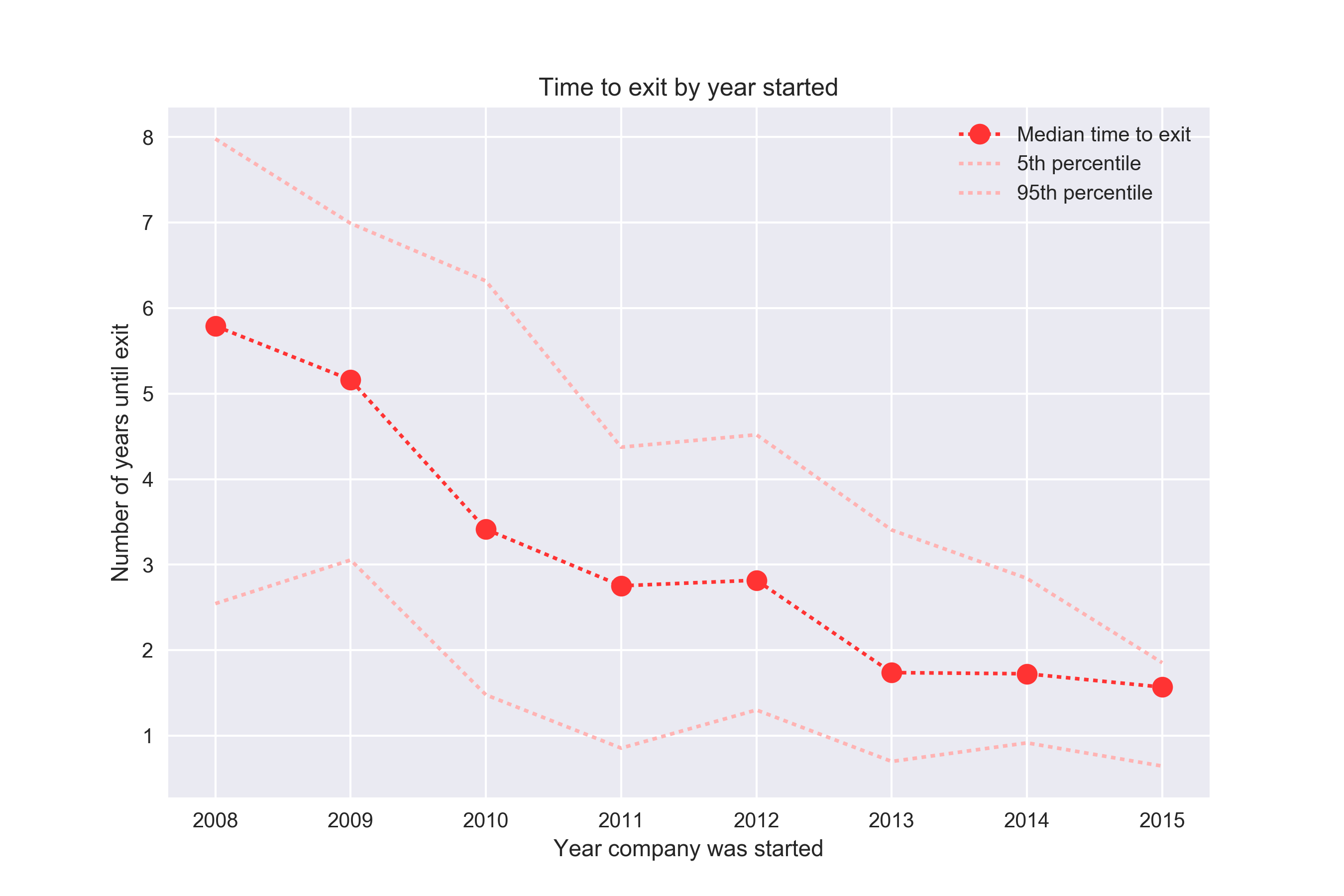
Здесь мы видим противоположную тенденцию. Согласно этой диаграмме, осуществить конверсию становится все легче и легче!
Так что же происходит на самом деле? Если задуматься, то все становится ясно: мы смешиваем данные за 2008 год (где компании имели 9 лет на то, чтобы конвертировать себя) и более поздние данные, например, за 2016 год (где у компаний был всего 1 год или менее). Мы не знаем, сколько компаний из группы 2016 года конвертируется в будущем и не можем учесть их в расчете.
Две представленные выше диаграммы хорошо иллюстрируют тот факт, что во многих случаях понятия «единый коэффициент конверсии» и «время до конверсии» лишены смысла. Эти показатели применимы лишь в тех случаях, когда конверсия имеет некоторый четкий верхний временной предел. Например, вероятно, логично будет измерять конверсию лендинга, ориентируясь на количество посетителей, перешедших по ссылке в течение часа. Однако во многих случаях, в частности, в отношении рассмотренных нами примеров про стартапы и Spotify, показатели «единый коэффициент конверсии» и «время до конверсии» неприменимы.
Правильный метод расчета коэффициентов конверсии. Когортные диаграммы
Рациональный подход к сравнению коэффициентов конверсии заключается в том, чтобы сравнить их в момент времени T, где T представляет собой некоторую временную задержку, например, 7 суток, 30 суток, 1 год и т.д. Например, чтобы сравнить коэффициенты конверсии для компаний из когорт 2012 и 2014 годов, мы сравниваем процент компаний из каждой когорты, конвертировавшихся в течение 24 месяцев с момента основания.
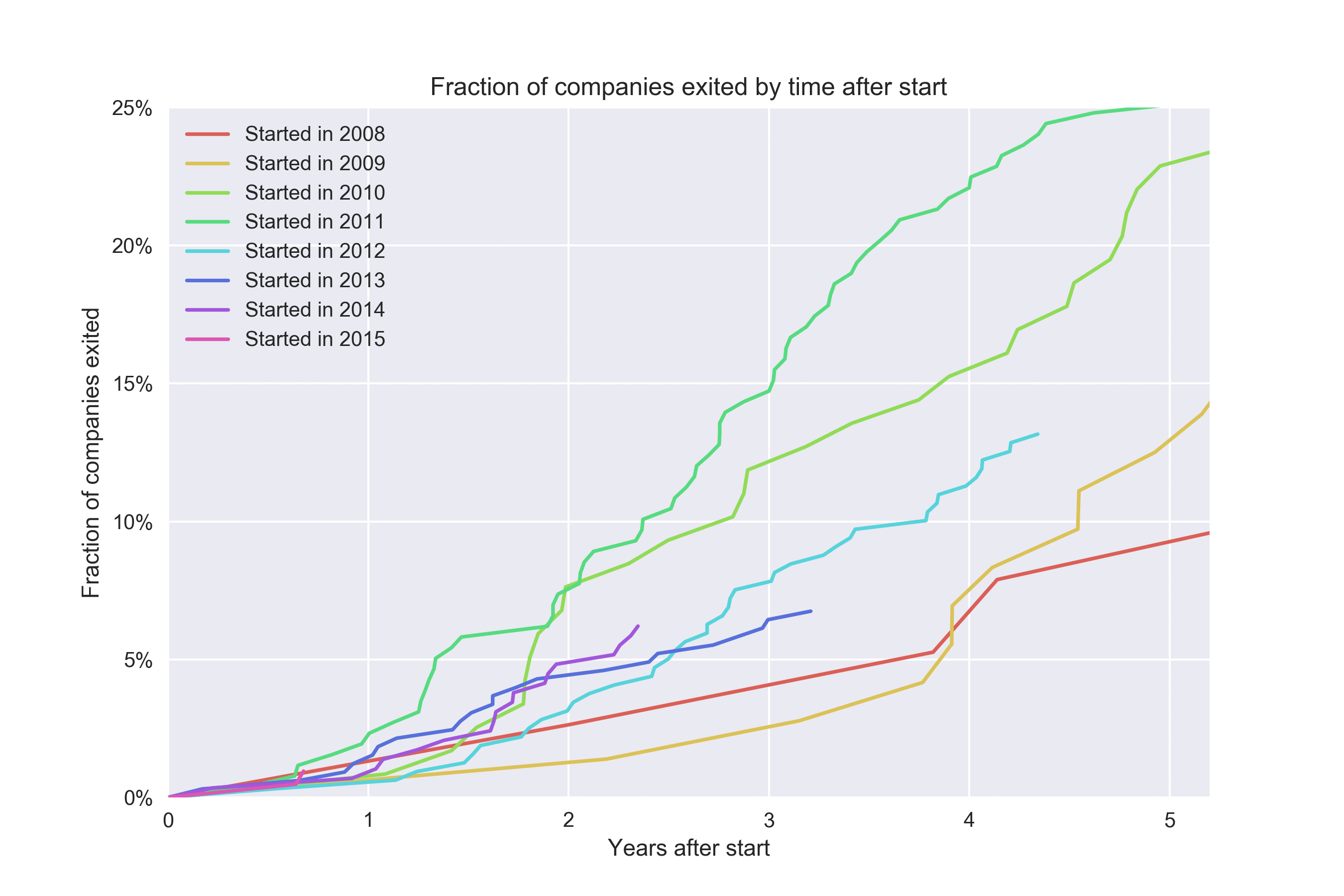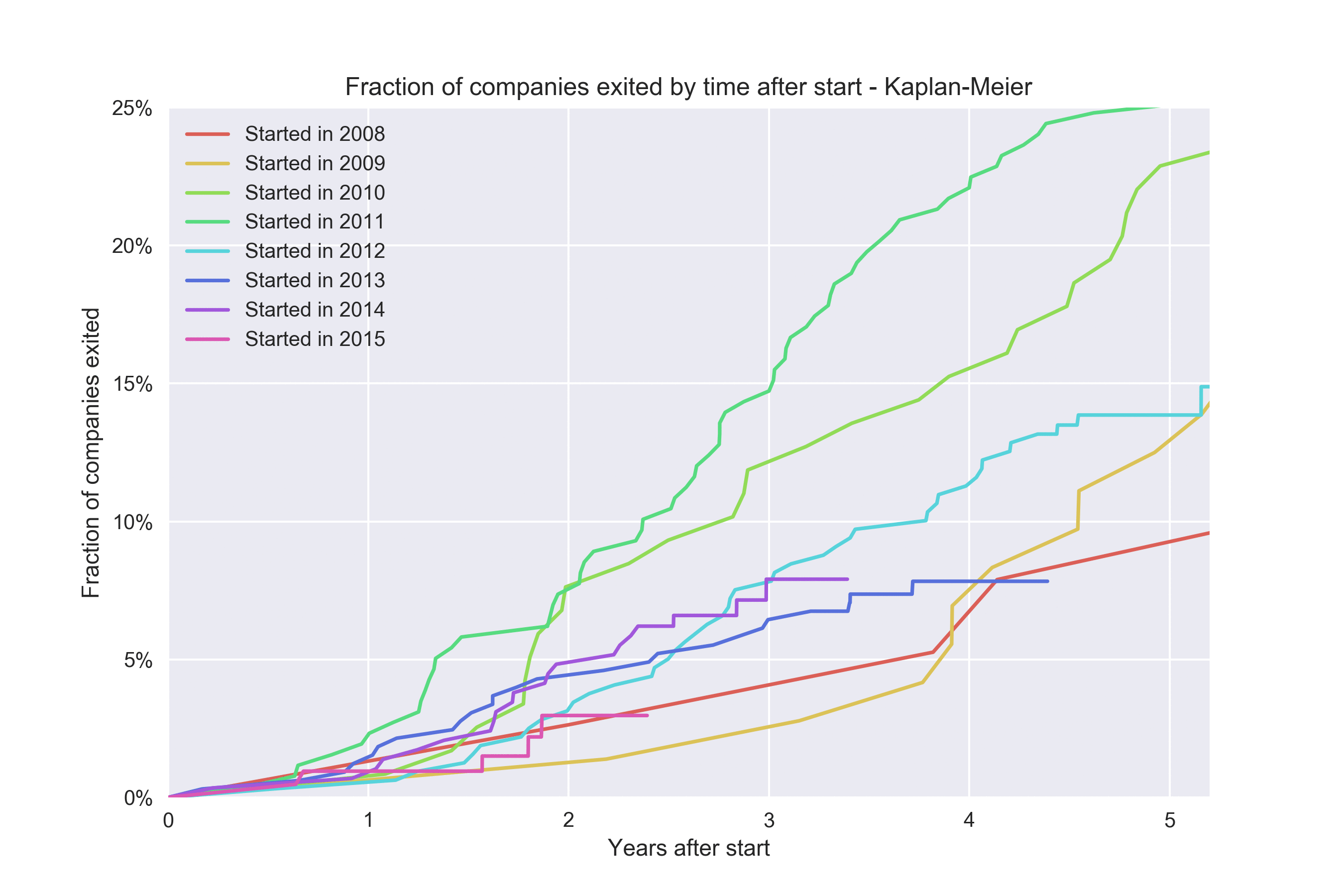
Мы можем распространить эту логику на все значения времени T и построить зависимость коэффициента конверсии от времени T для каждой когорты. Теперь мы можем выяснить, требуется ли стартапам, основанным в 2014 году, больше времени для конверсии, чем стартапам, основанным в 2008. Давайте посмотрим:
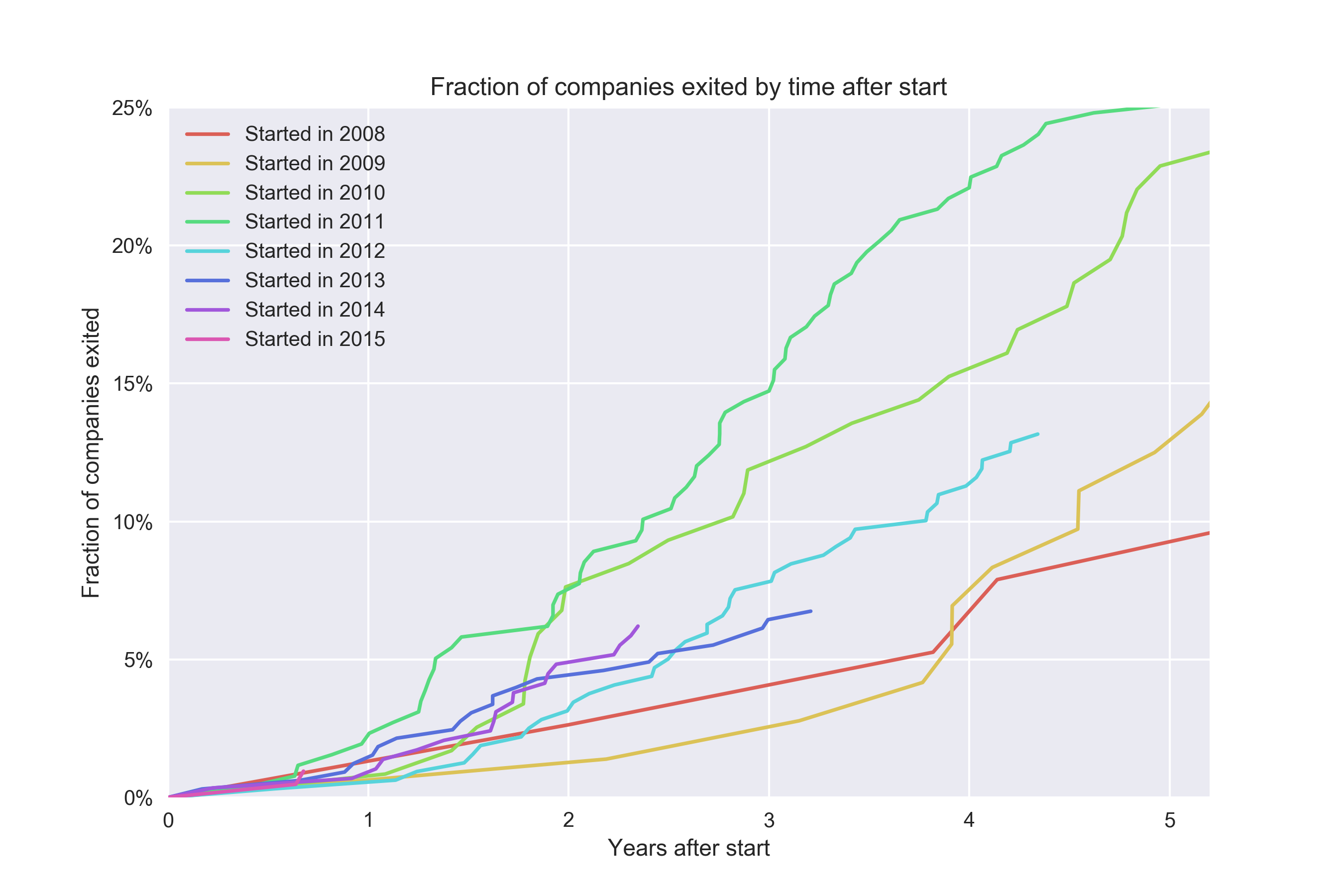
Точно не знаю, каким является «официальное» название подобной диаграммы, но обычно ее называют когортной диаграммой (cohort plot). Для каждой когорты мы сравниваем коэффициент конверсии в момент времени T. О когорте 2015 года мы немногое можем сказать, поскольку у нас просто нет данных за пределами первых ~5 месяцев.
Этот подход дает нам следующие возможности:
- Мы можем сравнить коэффициенты конверсии для различных когорт.
- Мы можем узнать, компании из каких когорт конвертируются быстрее.
Я считаю этот подход наилучшим для большинства ситуаций. Единственный его недостаток заключается в том, что идея расчета конверсии в момент времени T означает, что мы не можем получить информацию за текущий период. Например, было бы намного лучше, если бы могли оценить тенденцию для компаний, основанных в 2017 году. Мне нравятся метрики с быстрой отдачей. Так можем ли мы улучшить описанный выше подход? Оказывается, да.
Крутой метод расчета коэффициентов конверсии. Метод Каплана-Мейера
Метод Каплана-Мейера (Kaplan-Meier estimator) – это непараметрический метод, разработанный для оценки функции выживаемости (survival function). Нетрудно показать, что функция выживаемости – это единица минус коэффициент конверсии. Таким образом, два этих показателя, по сути, эквивалентны. Непараметричность метода является полезной особенностью в тех случаях, когда у нас нет информации о том, какое распределение мы моделируем.
Метода Каплана-Мейера хорош тем, что позволяет использовать данные, в которых нет наблюдений после некоторого момента. Лучше всего это можно проиллюстрировать, если немного расширить каждую когорту, чтобы они охватывали более широкий диапазон. Предположим, что мы хотим сравнить коэффициент конверсии для когорты 2008-2011 и когорты 2012-2015.
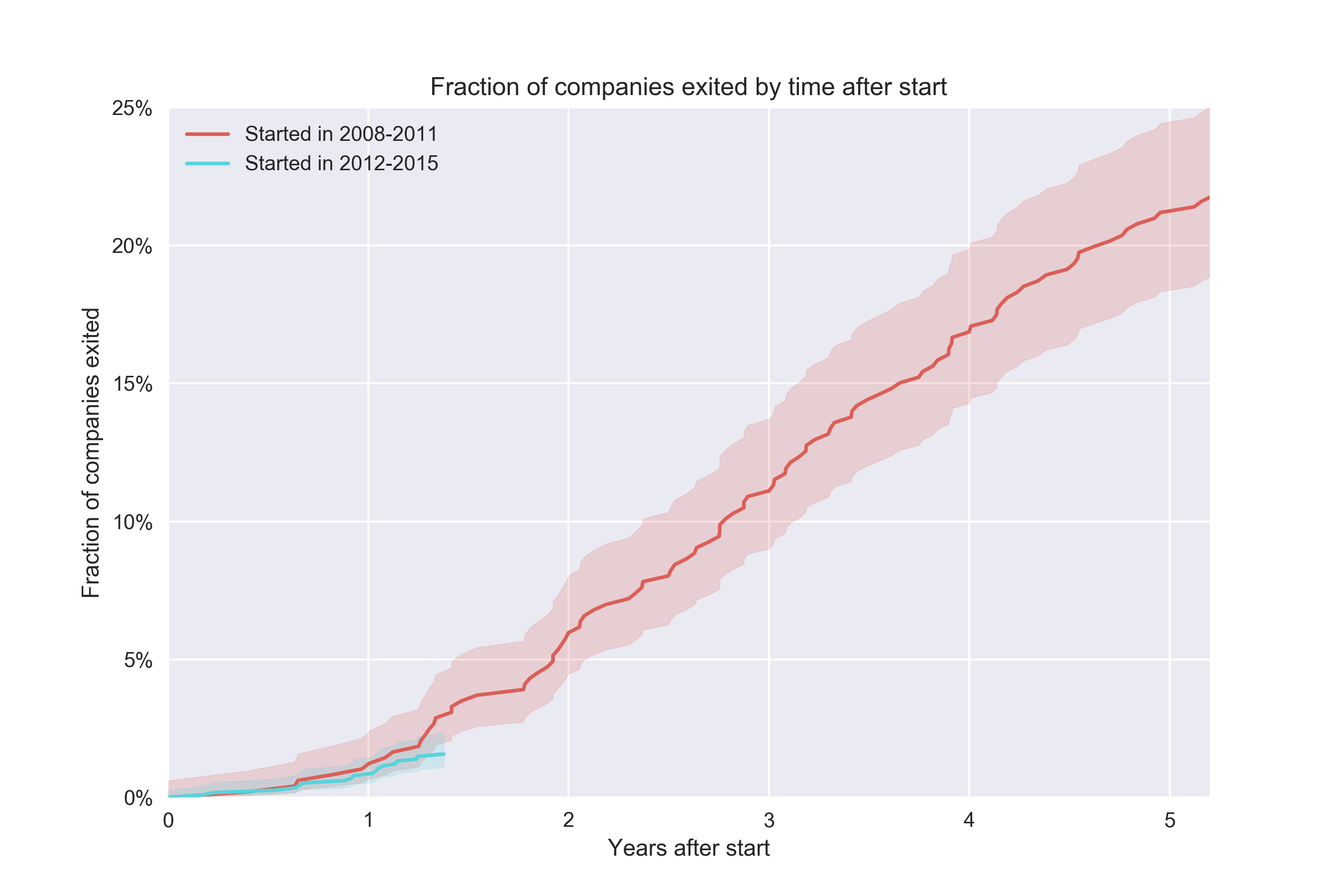
Построить эту диаграмму несложно, за исключением доверительного интервала. Чтобы получить коэффициент конверсии, буквально делим количество конвертировавшихся компаний на общее количество компаний.
Проблема заключается в том, что мы ничего не можем сказать о второй когорте за пределами отметки ~1.5 года, потому что это означало бы говорить о будущем. Эта когорта содержит компании, основанные до 31 декабря 2015 года включительно, у которых было чуть меньше 18 месяцев для того, чтобы конвертироваться. С другой стороны, самые старые компании в этой когорте, основанные в январе 2012, имели в запасе намного больше времени. Таким образом, должна существовать возможность создать более информативный график для этой когорты. Метод Каплана-Мейера позволяет нам решить эту задачу, благодаря «умному» подходу к «будущим» данным для различных наблюдений (в области анализа 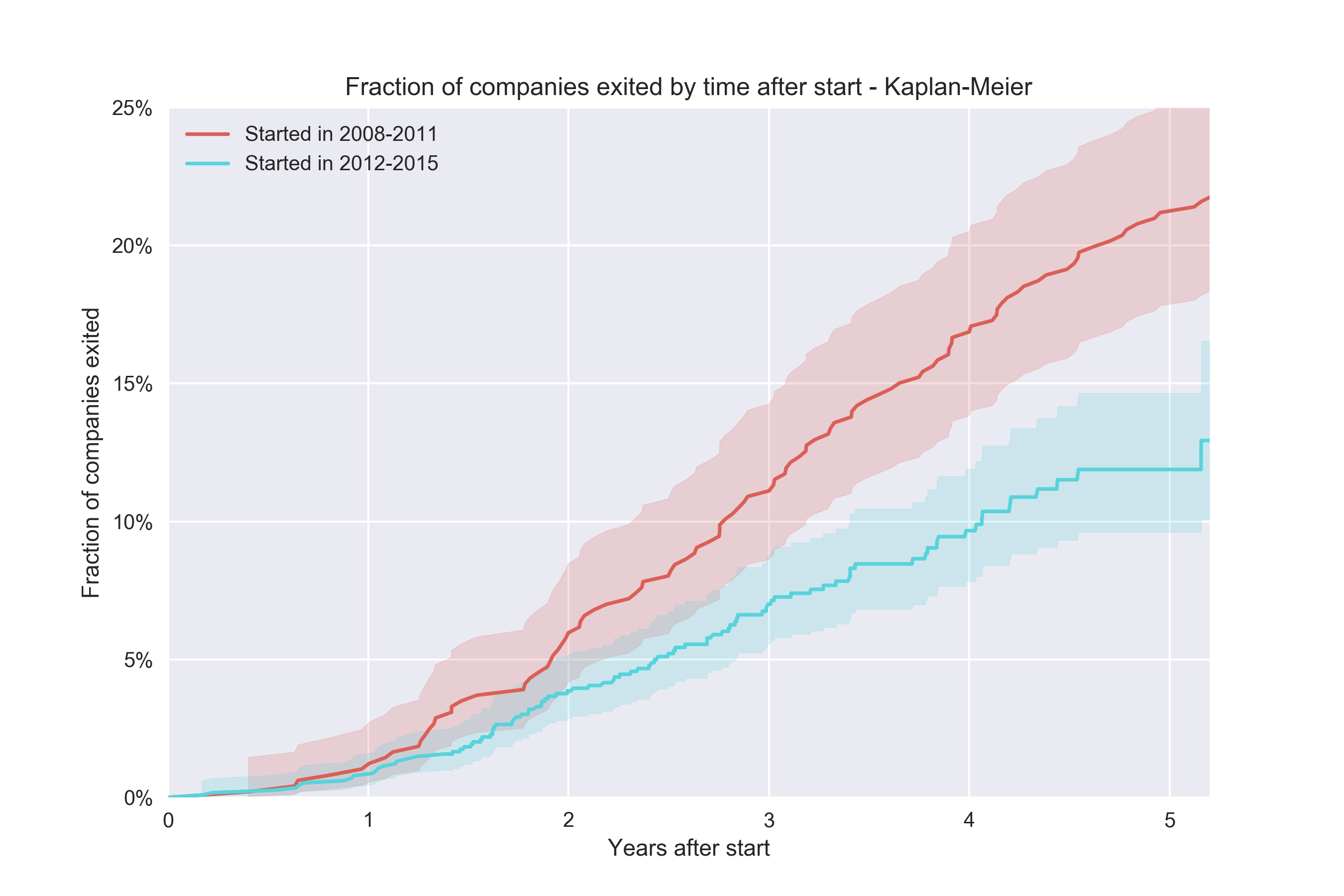 выживаемости используется термин «цензурированные наблюдения» («censored observations»)):
выживаемости используется термин «цензурированные наблюдения» («censored observations»)):
Реализация абсолютно несложная, впрочем, я использовал Python-пакет lifelines, чтобы построить график и доверительный интервал.
Теперь мы можем сделать вывод о том, что новые компании имеют меньший коэффициент конверсии, чем старые.
Если вы хотите самостоятельно реализовать метод Каплана-Мейера, то идея заключается в том, чтобы рассчитать «коэффициент выживаемости». Если мы начали со 100 компаний, и одна из них конвертировалась в момент времени 1, коэффициент выживаемости составит 99%. Мы продолжаем вычислять эти коэффициенты и перемножаем их. Если данные «цензурированы», мы просто убираем их из знаменателя:
n, k = len(te), 0
ts, ys = [], []
p = 1.0
for t, e in te:
if e: # whether the event was «observed» (converted) or not observed (may convert in the future)
p *= (n-1) / n
n -= 1
ts.append(t)
ys.append(100. * (1-p))
pyplot.plot(ts, ys, ‘b’)
Метод Каплана-Мейера позволяет нам получить немного больше информации для каждой когорты. Давайте посмотрим, как будет выглядеть диаграмма, если мы визуализируем отдельные когорты для каждого года основания с помощью метода Каплана-Мейера:
Эпилог
В предыдущей статье я создал инструмент для анализа выживаемости кода. Поскольку метод Каплана-Мейера специально предназначен для таких задач, я обновил свой инструмент, включив в него возможности этого метода. Ниже представлена кривая выживаемости отдельных строк кода самого Git:
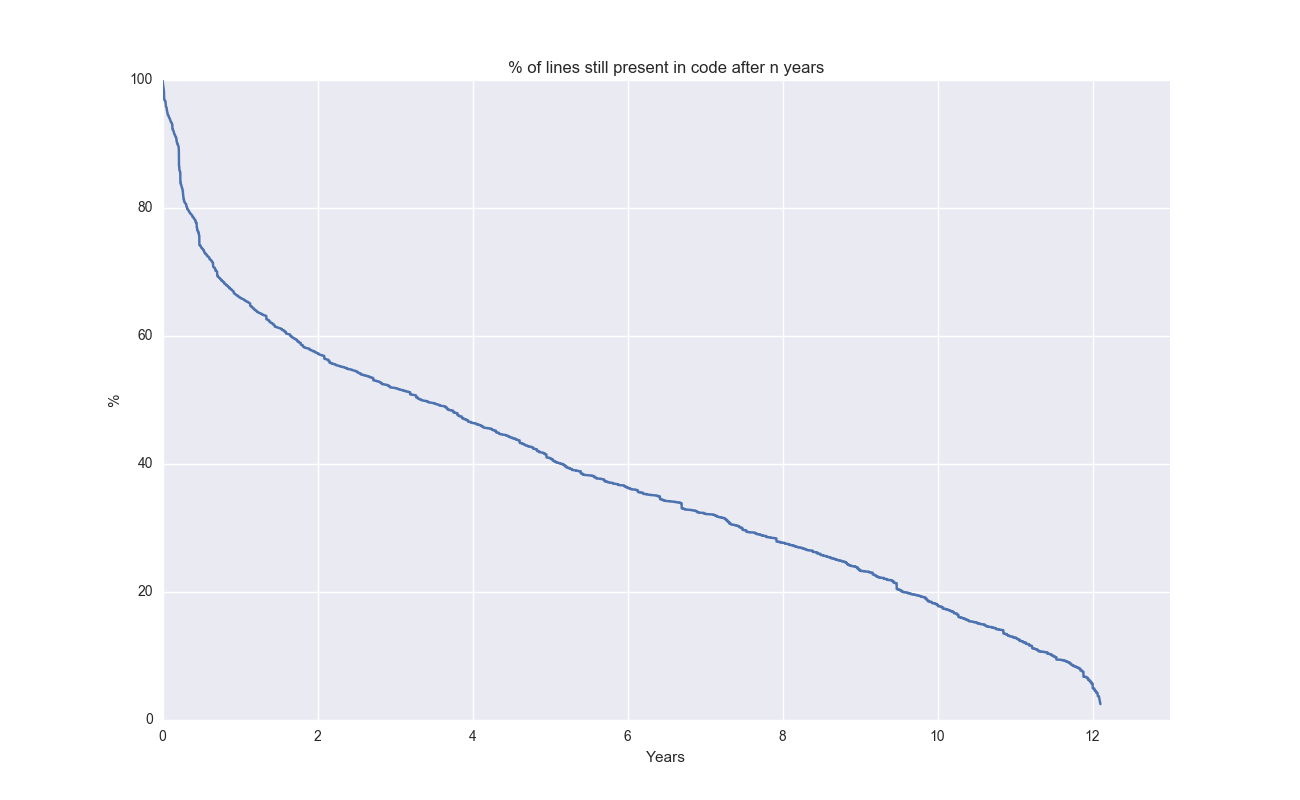
Интересный факт: несколько строк кода все еще присутствуют после 12 лет!
Заключение
Когда необходимо вычислить коэффициент конверсии и при этом имеет место временная задержка, помните: это не так просто, как может показаться!
Примечания
Для тех диаграмм, где не используется метод Каплана-Мейера, мы можем вычислить доверительные интервалы, с помощью следующего кода: scipy.stats.beta.ppf([0.05, 0.95], k+1, n-k+1)
Я говорил о том, что непараметрические методы – это хорошая вещь. При этом следует отметить, что это утверждение справедливо не всегда, поскольку данные методы не позволяют использовать априорное распределение и другие возможности, иногда позволяющие регуляризировать модель.
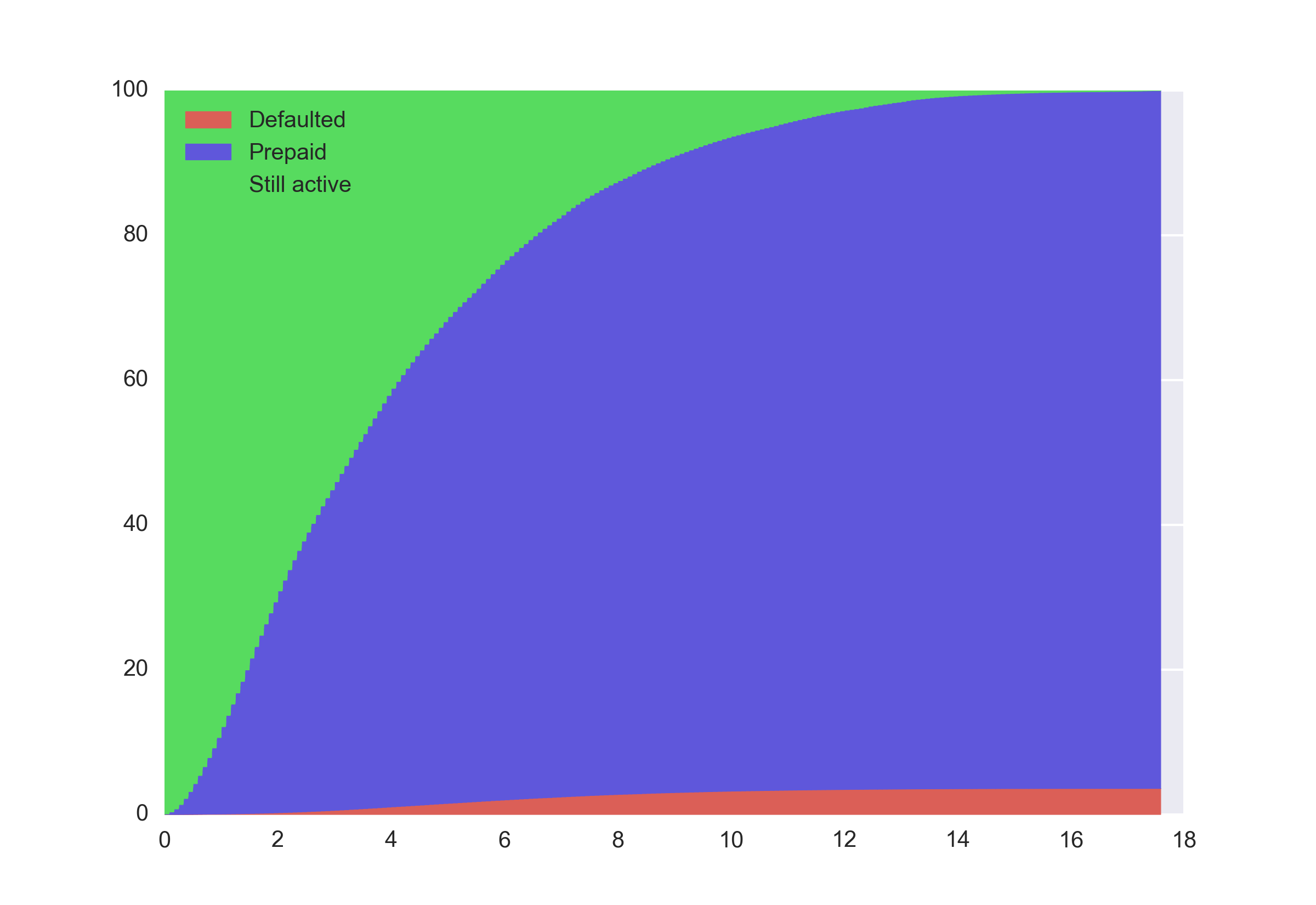
Я также хочу сказать, что бывают ситуации, в которых метод Каплана-Мейера неприменим. В тех случаях, когда мы имеем дело с чем-то более сложным, чем коэффициент конверсии (из состояния X в состояние Y), этот метод не работает. Например, давайте проанализируем набор данных о состоянии ипотечных кредитов Freddie Mac. В какой-то момент времени заемщик может выплатить сумму раньше срока (prepay) или допустить дефолт (default). Для многих недавних наблюдений у нас недостаточно исторических данных, чтобы определить конечный результат.
Поскольку возможны 2 различных конечных состояния (опережение и дефолт), мы не можем использовать метод Каплана-Мейера и должны применить другой подход. Простейшее решение заключается в том, чтобы просто вычислить нормализованную долю всех наблюдений, которые еще активны в момент времени T:
*Как обычно, код доступен на GitHub.
Перевод Станислава Перенко