Афоризм «данные — это новая нефть» (англ. data is the new oil) успел набить оскомину. Но и в гениальности ему не откажешь. Авторство цитаты приписывается британскому математику Клайву Хамби, разработавшему систему лояльности для торговой сети Tesco. Он произнес ее на конференции по маркетингу в 2006 году. Постепенно смысл этих слов доходит до широкой аудитории. И хотя люди продолжают воевать за нефть, контуры будущих конфликтов за данные проступают уже сейчас.
До недавних пор компании управляли традиционными активами — имуществом, деньгами, интеллектуальной собственностью. Цифровая эпоха принесла новый тип активов — данные. Это сырье, из которого производятся прогнозы, инсайты и очень большие деньги. Как пишет Economist, в XXI веке данные сыграют ту же роль, что нефть в XX-м. То есть станут главным фактором роста и перемен. Онлайн-сервисы работают на данных, как машины на бензине.
Объем накопленных миром данных в зеттабайтах:
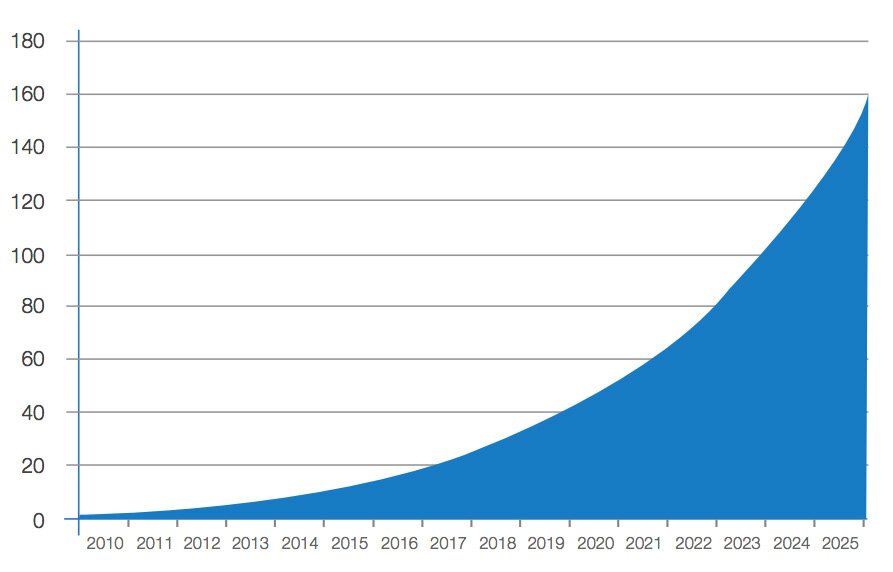
Исследование IDC, апрель 2017
Благодаря интернету вещей источниками данных стали любые устройства — от тостера до авиационного двигателя. Цифровой слепок человека все точнее. Все, что мы делаем, генерирует данные, а данные генерируют кэш. По прогнозу IDC, в 2017 году мировой рынок больших данных заработает $150,8 млрд, в 2020 году — $203 млрд.
Чем больше гуглишь, тем больше Google
Сначала интернет-компании использовали собранные данные для таргетинга рекламы. С расцветом технологий искусственного интеллекта стало ясно, что данные можно превратить в AI-сервисы, которые станут новым источником прибыли.
Многочисленные ИИ-стартапы создают умные сервисы на все случаи жизни: от анализа рентгеновских снимков до точного земледелия (подсказывают фермеру, на какие участки поля распылять гербициды). Пороги входа на рынок ИИ снижаются: растут вычислительные мощности, дешевеют датчики и железо, мощные инструменты для машинного обучения (TensorFlow от Google, DMTK от Microsoft, CatBoost от «Яндекса») открыты для любого программиста.
Главным конкурентным преимуществом на рынке искусственного интеллекта становятся сами данные. И вот ими-то, в отличие от софта, корпорации делиться не спешат. Аналитики IBM характеризуют состояние рынка данных как олигополию, где крупные игроки контролируют большую часть пирога. В интернете находится только 20% данных, остальные 80% хранятся в недрах компаний и организаций. Поэтому топ-менеджер IBM Дэвид Кенни считает данные валютой будущего.
Магия данных в том, что они помогают усовершенствовать продукт и привлечь больше пользователей, которые нагенерят еще больше данных, которые позволят привлечь еще больше пользователей. Данные — топливо современного рекламного рынка. Мировые ИТ-гиганты рвутся со своим бесплатным интернетом в страны третьего мира, чтобы заработать на данных офлайнового населения. Правда, на конференциях это принято называть устранением цифрового неравенства и желанием сделать мир лучше.
Лидерство Google, Facebook, Microsoft и Amazon в искусственном интеллекте во многом объясняется тем, что они владеют огромным количеством данных, которые нужны для обучения умных алгоритмов. Если вы тоже хотите заработать на ИИ, вам придется либо собрать, либо купить данные, которые по мере развития ИИ будут только дорожать. Известный на Западе техноскептик Евгений Морозов считает, что технологические титаны приватизируют наши данные, а это сулит нам новый феодализм.
Какими данными о человеке располагают крупнейшие в США брокеры данных
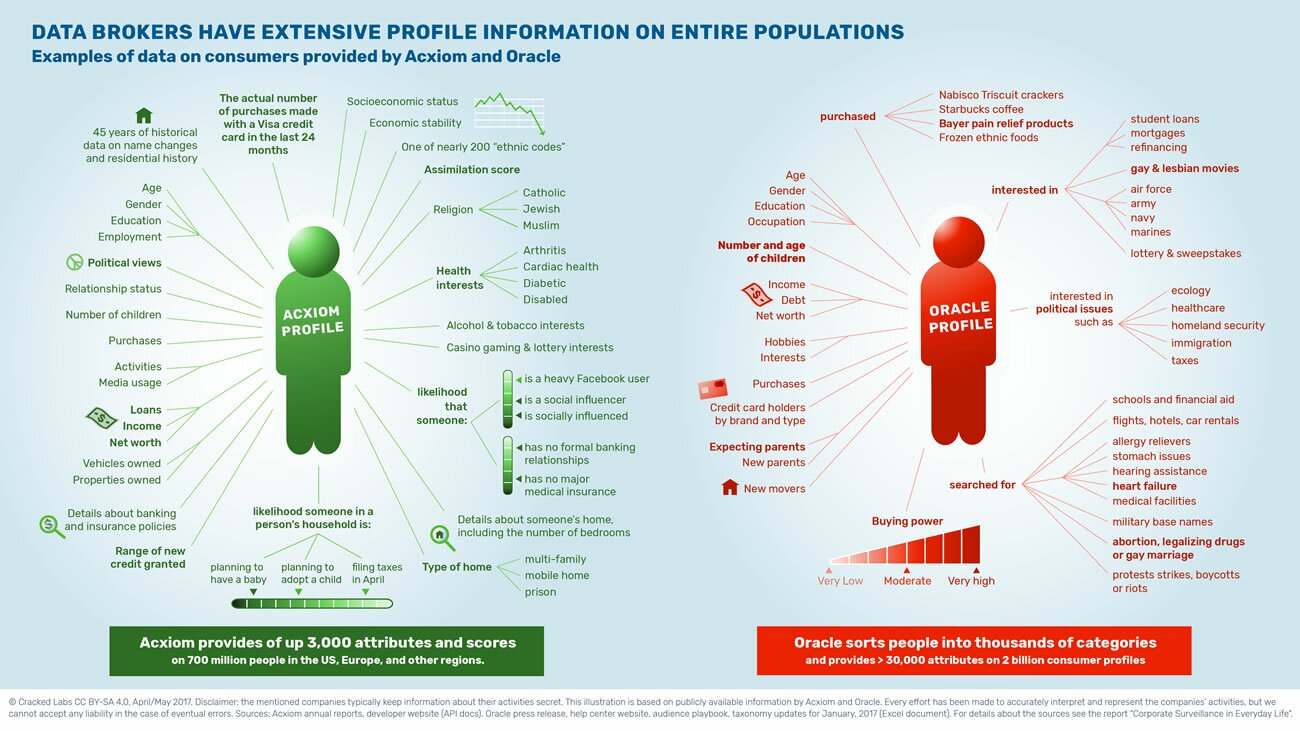
Исследование «Corporate Surveillance in Everyday Life», июнь 2017
Data-driven сделки
В экономике данных уже так не важно, окупается ли ИТ-проект. Когда есть большая аудитория и налажен сбор данных, монетизация — дело наживное. В этом свете 68-миллиардная оценка убыточного Uber, который многие считают пузырем, уже не кажется полным абсурдом. Самый дорогой стартап мира владеет крупнейшим массивом данных о рынке персональных перевозок (более 5 млрд поездок). Равно как и Tesla — не просто модный электрокар, а база данных о вождении на совокупной дистанции более 2 млрд км. Она дает компании фору в создании технологии беспилотного вождения. У разработчика беспилотных авто Waymo (принадлежит Alphabet) пока на порядок меньше данных.
Самым ценным активом обанкротившейся гемблинговой компании Caesars Entertainment оказались данные о 45 миллионах участников программы лояльности. Их оценили в $1 млрд.
Корпорации могут позволить себе купить компании, которые владеют нужной им базой пользователей. Этим объясняются многие крупнейшие сделки последних лет. Facebook купил Instagram и WhatsApp, Microsoft купил LinkedIn и т.д. Это вызывает беспокойство антимонопольных властей. В процессе согласования сделки по поглощению WhatsApp Facebook обещал не объединять данные двух компаний, но в прошлом году таки начал это делать. За это Еврокомиссия оштрафовала соцсеть на $122 млн.
Экономика данных требует от регуляторов новых подходов. Им придется быть не менее изобретательными, чем те, кого они регулируют. Чтобы не допустить диктата монополий, власти обязывают крупняк делиться данными с новыми проектами. Например, в Германии страховщики должны делиться с маленькими фирмами статистикой о страховых случаях. В следующем году вступят в силу европейские нормативы о защите данных. Интернет-сервисы будут обязаны получать от пользователей явное согласие на то, как будут использоваться их данные, а также позволить им экспортировать свои данные для передачи другим компаниям.
Чтобы конкурировать с гигантами, более мелкие игроки могут собираться в data-кооперативы. Так, крупнейшие немецкие медиа объединили большие данные с тысячи своих сайтов на общей платформе Emetriq, чтобы снизить свою зависимость от Google и Facebook, контролирующих 85% мирового рекламного рынка.
Легально торговать данными гораздо труднее, чем нефтью. Каждый датасет уникален, такой актив сложно оценить. Правовой базы еще нет, каждый контракт сочиняется с нуля и содержит десятки страниц о том, как покупатель будет использовать и защищать данные. Oracle разрабатывает единую инфраструктуру для обмена данными, которая позволит ее клиентам покупать и продавать свои базы данных в безопасной облачной среде.
Есть интересные примеры бартера: Национальная служба здравоохранения Великобритании предоставила DeepMind (ИИ-подразделение Alphabet) доступ обезличенным данным 1,6 млн пациентов, чтобы умные алгоритмы помогали врачам лечить пациентов с почечной недостаточностью.
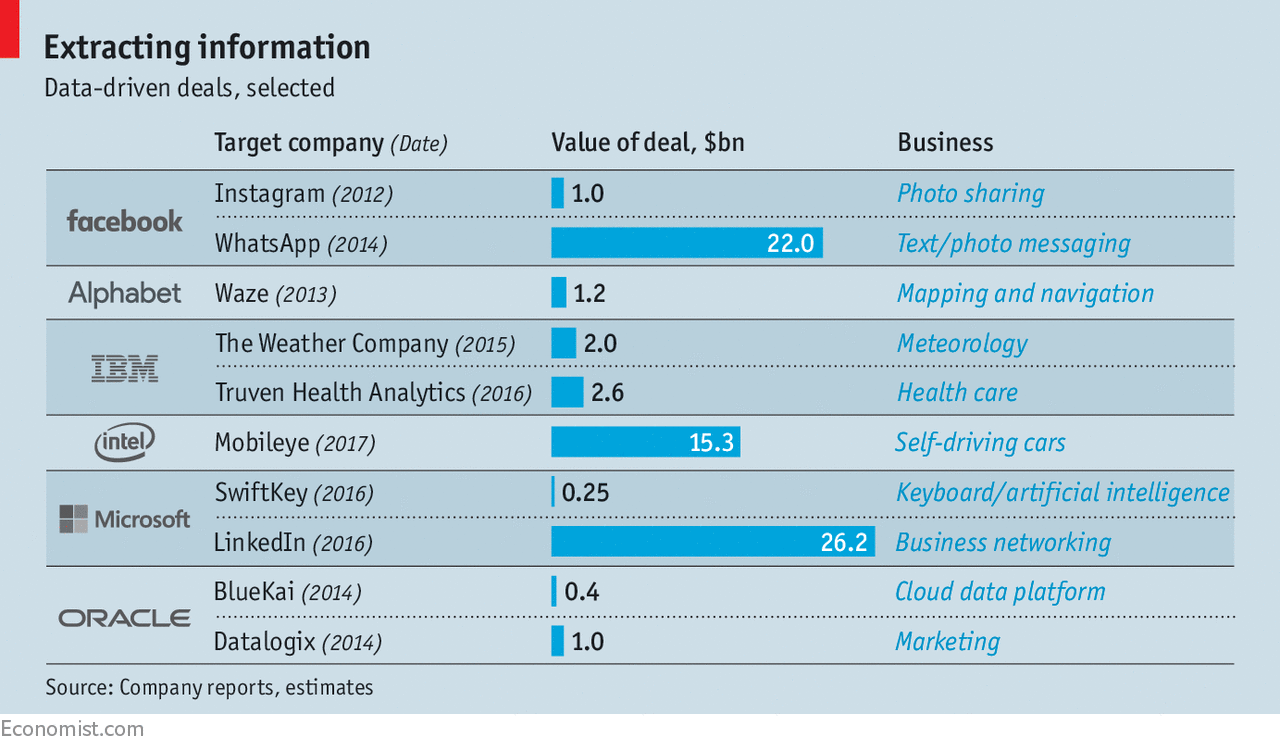
Инфографика журнала The Economist
Верните нам наши данные
Что все это значит для пользователей? Data-driven подход приводит к тому, что ИТ-продукты становятся все удобнее, а контент — все интереснее. Люди слишком привыкли к бесплатным онлайн-сервисам и не отдают себе отчета в том, за чей счет банкет. Так родился еще один расхожий афоризм: «Если ты не платишь за товар, сам становишься товаром» (англ. if you’re not paying for the product, you are the product).
Британцы очень возмущались, когда производитель бесплатного антивируса AVG решил заработать на продаже их поисковых запросов. Некоторые даже объявили бойкот. Представители AVG тогда парировали, что они открыто внесли изменения в свою политику конфиденциальности, а другие делают то же самое без ведома пользователей. Но даже платные сервисы собирают данные, чтобы потом использовать их для создания смежных продуктов.
Впереди нас ждет много битв за то, кто должен владеть данными и кто может на них зарабатывать. Де факто данными владеют и распоряжаются платформы, которые их собирают, а де юре — еще предстоит выяснить. Данные можно скопировать и продать много раз. Это несет угрозу утечек и нецелевого использования, которое может причинить вред пользователю.
Потенциал конфликта в том, что люди не понимают, какие данные о них собираются и как они будут использоваться. Они подписываются под нечитанными пользовательскими соглашениями, которые составлены в интересах бизнеса и разрешают передачу данных третьей стороне. В перспективе наши данные могут свидетельствовать против нас. Например, сначала человек покупает симку, а потом ему не одобряют кредит.
Но велики ли наши шансы на информированное согласие? В прошлом году норвежские правозащитники прочитали правила пользования 33 самых популярных в стране приложений. Это заняло у них 30 часов. А недавно британский провайдер публичного Wi-Fi добавил в пользовательское соглашение право отправить юзера сети чистить общественные туалеты. За две недели эксперимента на такие условия подписались 22 тысячи человек.
Колумнист и писатель Евгений Морозов считает несправедливым, что на данных пользователей зарабатывают все, кроме них самих. Он призывает относиться к данным как к природным ресурсам, которые должны принадлежать народу, а не корпорациям. Тогда люди сами смогут создавать для себя полезные сервисы. «Верните нам наши данные. <…> Если всеми ресурсами завладеют Google и Facebook, они позволят нам дышать, только когда мы смотрим рекламу», — говорит он.
В западных медиа все чаще звучит мысль о том, что ИИ-сервисы — продукт не только разработчиков, но и тысяч пользователей, послушно заполняющих регистрационные формы. По мнению правозащитников, люди заслуживают более весомой компенсации, чем бесплатные сервисы. Но сколько стоят наши данные?
В 2013 году американский студент Федерико Занниер продал свои данные всем желающим на Kickstarter. В течение 50 дней он фиксировал все свои действия в интернете: посещенные сайты, скриншоты просмотренных страниц, переписку с друзьями, логи приложений, движения мыши, историю передвижений. Во время работы на компьютере каждые 30 секунд его фотографировала веб-камера.
Цифровой архив Федерико за день стоил $2, весь массив — $250. «Если бы больше людей сделали то же, что и я, рекламодатели платили бы за наши данные напрямую, — написал он на странице проекта. — Это кажется безумным, равно как и отдавать наши данные бесплатно».
Занниер собрал $2,733 от 213 бэкеров.
Через год эксперимент повторил голландец Шон Баклз. С помощью онлайн-аукциона он выручил за свои персональные данные 350 евро. «Обычно данные людей продаются по 50 центов, но я выложил самую интимную информацию о себе, — отметил он. — Не знаю, является ли эта сумма достаточной».
Датасет включал медицинские записи, переписку в электронной почте и соцсетях, историю перемещений, личный календарь, потребительские предпочтения, историю браузера и личные записи. Массив выкупило издание The Next Web, чтобы блеснуть этим прецедентом на конференции. Это соответствовало цели акции — привлечь внимание к этике данных. «Приватность — это право каждого быть незаметным и самостоятельно решать, какой информацией делиться и с кем», — писал Баклз. Вырученные деньги он пожертвовал голландской правозащитной организации Bits for Freedom.
Но на практике компании покупают аудиторные данные оптом, а не в розницу. Нужно быть очень успешным человеком, чтобы ваши данные стоили больше доллара. В 2013 году Financial Times опубликовала калькулятор для расчета стоимости персональных данных. Цены могли устареть, зато этот инструмент наглядно показывает, какие сведения делают вас наиболее привлекательным объектом для рекламодателей (беременность, владение яхтой, страсть к путешествиям и т.д.).

Калькулятор от FT
Будем реалистами: большинство людей никогда не удалятся из соцсетей и не прекратят пользоваться условно бесплатными сервисами. Жесткие ограничения на использование данных запрут этот невероятно ценный актив в частных дата-центрах и убьют на корню сотни будущих интеллектуальных сервисов, которые действительно сделают мир лучше. Для компаний наши данные все равно не бесплатны. Чтобы хранить растущие цифровые богатства, им приходится покупать новые серверы и платить за электричество.
Европейцы предлагают создавать биржи персональных данных, которые позволят пользователям монетизировать свое цифровое ДНК. Такой подход вернет обывателям контроль над сбором и использованием сведений о них. На Западе возникла целая ниша стартапов, которые помогают людям распорядиться своими данными: CitizenMe, Datacoup, Mass Network, Hub of All Things, Cozy, Digi.me и другие. А тайваньский стартап Bitmark делает это с помощью блокчейна.
Необходимость платить за аудиторные данные ударит по заработкам ИТ-компаний. С другой стороны, им может быть даже выгодна такая схема, ведь добровольно переданная информация гораздо точнее обрывочных сведений серого происхождения.
Все, что вы делаете в интернете, может быть использовано против вас
Компании подчеркивают, что продают и используют только обезличенные данные. Но это не снимает тревоги обывателей. Каноничный кейс торговой сети Target, чья рекомендательная система узнала о беременности школьницы раньше самой школьницы, спровоцировал горячие споры об этике больших данных. Чтобы спасти репутацию, компания подкорректировала алгоритм. Он начал разбавлять товары для беременных более нейтральными предложениями. Эта история — отличный пример того, что из наших данных можно добыть выводы, которых мы сами о себе не знаем.
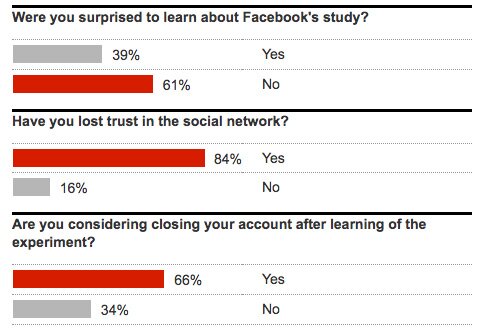
Результаты опроса читателей The Guardian
В 2012 году Facebook провела психологический эксперимент над 689 тысячами человек. Половине выборки алгоритм показывал позитивный контент, другой половине — негативный, а потом анализировал реакцию пользователей. Целью исследования было доказать влияние соцсетей на настроения людей. Результаты были более чем убедительны. В 2014 году, когда их опубликовали, Facebook попала в настоящий социальный шторм. Из пользователей сделали подопытных крыс, писали тогда рассерженные блогеры. Широкая публика была поражена, что данные можно использовать не только для таргетирования рекламы, но и для манипулирования людьми.
В прошлом году соцсеть захлестнула новая волна критики. Facebook обвинили в том, что ее алгоритм формирования новостной ленты (питающийся данными о пользователях) привел к радикализации пользователей, распространению фейковых новостей и тем самым помог Трампу стать президентом.
Большинство скандалов из области data ethics связаны с несанкционированным сбором данных. Например, производители SmartTV не раз попадались на слежке за пользователями. По прогнозу Gartner, к 2018 году половина нарушений деловой этики будут нарушениями этики данных. Последствиями для компаний будут репутационный ущерб и юридические санкции.
И без того размытая грань между персональными и большими данными тоньше, чем кажется. Данные интернет-запросов нередко содержат личную информацию и могут быть деанонимизированы. Cопоставление анонимизированных больничных записей и новостей со словом «госпитализирован» позволило исследователям опознать 43% пациентов.
Ярче всех по теме приватности в мире больших данных высказался питерский фотограф Егор Цветков. В прошлом году он отменно хайпанул со своим проектом You face is big data. Цветков сфотографировал случайных незнакомцев в метро, а потом нашел их профили «Вконтакте» через нейросетевой фотопоиск FindFace.
Интеллектуальные алгоритмы принятия решений, которые обучаются на данных, могут быть предубеждены. Например, американские судьи используют программы для предсказания рецидива преступления. Это помогает им определиться с суммой выдачи обвиняемого под залог и тяжестью наказания. В прошлом году СМИ обвинили один из самых популярных алгоритмов такого рода — программу COMPAS от компании Northpointe — в расизме.

Впоследствии белый американец был три раза арестован за хранение наркотиков, афроамериканец — ни одного
Только 20% потенциальных рецидивистов действительно совершили преступления. При этом количество ошибочных предсказаний рецидива для чернокожих оказалось вдвое выше, чем для белых.