
Сводные таблицы (pivot table) – невероятно удобный инструмент для анализа табличных данных. Эта статья рассказывает о том, как использовать элегантную функциональность сводных таблиц, реализованную в библиотеке Pandas, для исследования и анализа данных.
Возможность создавать сводные таблицы присутствует в электронных таблицах и других программах, оперирующих табличными данными. Сводная таблица принимает на входе данные из отдельных столбцов и группирует их, формируя двумерную таблицу, реализующую многомерное обобщение данных. Чтобы ощутить разницу между сводной таблицей и операцией GroupBy, можно представить себе сводную таблицу, как многомерный вариант агрегации посредством GroupBy. То есть данные разделяются, преобразуются и объединяются, но при этом разделение и объединение осуществляются не по одномерному индексу, а по двумерной сетке.
Преимущества сводных таблиц
Для примеров в этом разделе, мы будем использовать набор данных о пассажирах «Титаника», доступный посредством библиотеки seaborn.
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
Этот набор данных содержит обширную информацию о каждом пассажире того злополучного рейса, в том числе пол, возраст, класс, стоимость билета и многое другое.
Реализация сводной таблицы вручную
Чтобы изучить эти данные, возможно, потребуется сгруппировать пассажиров по таким параметрам, как пол, выжил или нет, или на основании какой-либо комбинации параметров. Если вы прочитали предыдущий раздел, у вас может появиться искушение применить к этим данным операцию GroupBy. Например, давайте вычислим процент выживших для каждого пола:
titanic.groupby('sex')[['survived']].mean()
| survived | |
|---|---|
| sex | |
| female | 0.742038 |
| male | 0.188908 |
Сразу же можно сделать вывод о том, что из каждых четырех женщин, находившихся на борту, выжили три, в то время как из каждых пяти мужчин выжил только один!
Это интересная информация, но мы можем пойти дальше и выяснить взаимосвязь между показателем выживаемости и двумя другими параметрами, такими как пол и, например, класс. Используя терминологию GroupBy, мы могли бы сформулировать последовательность наших действий следующим образом: группируем по (group by) классу и полу, отбираем (select) выживших, применяем (apply) агрегацию по среднему, объединяем (combine) результирующие группы и преобразуем (unstack) иерархический индекс, чтобы раскрыть скрытую многомерность. Выразим это в коде:
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
Теперь мы имеем четкое представление о том, как пол и класс повлияли на выживаемость, но код становится немного громоздким. Хотя каждый шаг этой последовательности вполне понятен в свете рассмотренных выше инструментов, тем не менее длинную строку кода достаточно трудно читать и использовать. Подобные операции широко распространены, в связи с чем библиотека Pandas имеет в своем составе специальный метод pivot_table, лаконично реализующий данный тип многомерной агрегации.
Синтаксис сводных таблиц
Ниже представлен эквивалент рассмотренной выше операции, реализованный с помощью метода pivot_table объекта DataFrame:
titanic.pivot_table('survived', index='sex', columns='class')
Это выражение намного легче читается, по сравнению с эквивалентным выражением для GroupBy, и дает тот же результат. Как можно было ожидать, в случае трансатлантического рейса начала 20-го века, больше шансов выжить было у женщин и пассажиров более высоких классов. Женщины из первого класса спаслись почти все (привет, Кейт!), в то время как из каждых десяти мужчин с билетами третьего класса выжил только один (прости, Лео!).
Многоуровневые сводные таблицы
Точно так же, как при использовании GroupBy, группирование в сводной таблице может иметь несколько уровней и задаваться посредством различных параметров. Например, в качестве третьего измерения нас может заинтересовать возраст. Мы разделим возраст на интервалы, с помощью функции pd.cut:
age = pd.cut(titanic['age'], [0, 18, 80])
titanic.pivot_table('survived', ['sex', age], 'class')
| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 80] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 80] | 0.375000 | 0.071429 | 0.133663 |
Мы можем сделать то же самое со столбцами. Давайте добавим информацию о стоимости билета, используя функцию pd.qcut, чтобы автоматически рассчитать квантили:
fare = pd.qcut(titanic['fare'], 2)
titanic.pivot_table('survived', ['sex', age], [fare, 'class'])
| fare | (14.454, 512.329] | [0, 14.454] | |||||
|---|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third | |
| sex | age | ||||||
| female | (0, 18] | 0.909091 | 1.000000 | 0.318182 | NaN | 1.000000 | 0.714286 |
| (18, 80] | 0.972973 | 0.914286 | 0.391304 | NaN | 0.880000 | 0.444444 | |
| male | (0, 18] | 0.800000 | 0.818182 | 0.178571 | NaN | 0.000000 | 0.260870 |
| (18, 80] | 0.391304 | 0.030303 | 0.192308 | 0 | 0.098039 | 0.125000 | |
В результате получим четырехмерную агрегацию, демонстрирующую взаимосвязь между соответствующими величинами.
Дополнительные параметры сводной таблицы
Полная сигнатура вызова метода pivot_table объекта DataFrame является следующей:
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean',
fill_value=None, margins=False, dropna=True)
Выше мы рассмотрели три первых параметра. Теперь давайте обсудим остальные. Параметры fill_value и dropna задают способ обработки отсутствующих данных. Их использование не вызывает затруднений, поэтому мы не будем приводить примеры.
Параметр aggfunc задает тип агрегации. По умолчанию его значение равно ‘mean‘. Как и в случае GroupBy, тип агрегации можно задать либо с помощью предопределенной строки (например, ‘sum’, ‘mean’, ‘count’, ‘min’, ‘max’ и др.), либо посредством функции, реализующей агрегацию (например, np.sum(), min(), sum() и др.). Кроме того, этот параметр может быть задан в виде словаря, отображающего столбцы на любые из желаемых значений, перечисленных выше:
titanic.pivot_table(index='sex', columns='class',
aggfunc={'survived':sum, 'fare':'mean'})
| fare | survived | |||||
|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third |
| sex | ||||||
| female | 106.125798 | 21.970121 | 16.118810 | 91 | 70 | 72 |
| male | 67.226127 | 19.741782 | 12.661633 | 45 | 17 | 47 |
Обратите внимание, в данном случае мы не задали параметр values, потому что он задается автоматически, когда параметр aggfunc представлен в виде отображения.
Иногда требуется вычислить обобщенные значения по каждой группе. Это можно сделать с помощью параметра margins:
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
| class | First | Second | Third | All |
|---|---|---|---|---|
| sex | ||||
| female | 0.968085 | 0.921053 | 0.500000 | 0.742038 |
| male | 0.368852 | 0.157407 | 0.135447 | 0.188908 |
| All | 0.629630 | 0.472826 | 0.242363 | 0.383838 |
Представленный выше код автоматически дает нам процент выживших в зависимости от пола без учета класса, в зависимости от класса без учета пола, а также общий процент выживших, составляющий 38%.
Пример. Данные о рождаемости
В качестве более интересного примера давайте рассмотрим свободно доступные данные о рождаемости в США, предоставленные Центрами по контролю и профилактике заболеваний (Centers for Disease Control and Prevention, CDC). Данные можно загрузить по ссылке: https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv.
Этот набор данных был детально проанализирован группой Эндрю Джелмана (Andrew Gelman). Подробности можно найти в этой статье.
# shell command to download the data:
!curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv
births = pd.read_csv('births.csv')
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 258k 100 258k 0 0 1935k 0 --:--:-- --:--:-- --:--:-- 1943k
--------------------------------------------------------------------------- NameError Traceback (most recent call last)in () 2 get_ipython().system(u'curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv'>) 3 ----> 4 births = pd.read_csv('births.csv') NameError: name 'pd' is not defined
Набор данных имеет достаточно простую структуру: количество новорожденных сгруппировано по дате и полу.
births.head()
| year | month | day | gender | births | |
|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1 | F | 4046 |
| 1 | 1969 | 1 | 1 | M | 4440 |
| 2 | 1969 | 1 | 2 | F | 4454 |
| 3 | 1969 | 1 | 2 | M | 4548 |
| 4 | 1969 | 1 | 3 | F | 4548 |
Детально разобраться в этих данных нам поможет сводная таблица. Давайте добавим столбец «decade» (десятилетие) и посмотрим, как изменялось количество новорожденных каждого пола в зависимости от десятилетия:
births['decade'] = 10 * (births['year'] // 10)
births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
| gender | F | M |
|---|---|---|
| decade | ||
| 1960 | 1753634 | 1846572 |
| 1970 | 16263075 | 17121550 |
| 1980 | 18310351 | 19243452 |
| 1990 | 19479454 | 20420553 |
| 2000 | 18229309 | 19106428 |
Сразу же видно, что в каждом десятилетии количество новорожденных мальчиков превышает количество новорожденных девочек. Чтобы подробнее изучить эту тенденцию, давайте визуализируем общее количество новорожденных по годам с помощью встроенных в библиотеку Pandas инструментов визуализации:
%matplotlib inline
import matplotlib.pyplot as plt
sns.set() # use seaborn styles
births.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot()
plt.ylabel('total births per year');
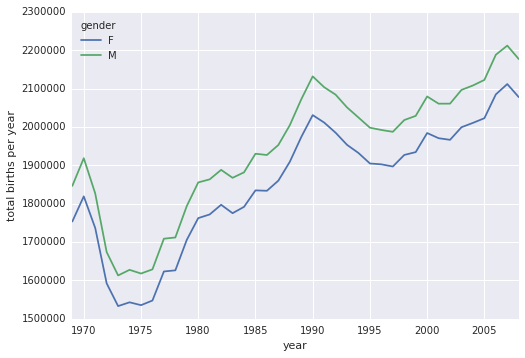
С помощью простой сводной таблицы и метода plot(), мы быстро получаем наглядное представление о динамике рождаемости мальчиков и девочек в зависимости от года. При оценке на глаз видно, что в течение последних 50-ти лет количество новорожденных мальчиков примерно на 5% превышало количество новорожденных девочек.
Продолжаем исследование данных
Хотя это необязательно относится к сводным таблицам, тем не менее существует дополнительная интересная информация, которую мы можем извлечь из этого набора данных с помощью рассмотренных инструментов библиотеки Pandas. Необходимо начать с очистки данных, чтобы избавиться от аномальных значений, связанных с несуществующими датами, такими как 31-е июня или 99-е июня. Мы удалим все аномальные значения с помощью операции робастного ограничения среднеквадратичного отклонения (robust sigma-clipping):
# Some data is mis-reported; e.g. June 31st, etc.
# remove these outliers via robust sigma-clipping
quartiles = np.percentile(births['births'], [25, 50, 75])
mu = quartiles[1]
sig = 0.7413 * (quartiles[2] - quartiles[0])
births = births.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)')
Затем преобразуем значения в столбце «day» к целочисленному типу. Исходно эти значения являются строками, потому что некоторые из них представляют собой строку «null»:
# set 'day' column to integer; it originally was a string due to nulls births['day'] = births['day'].astype(int)
Наконец, мы можем объединить день, месяц и год, чтобы создать индекс «date» (дата). Это позволит нам легко вычислить день недели, соответствующий каждой строке:
# create a datetime index from the year, month, day births.index = pd.to_datetime(10000 * births.year + 100 * births.month + births.day, format='%Y%m%d') births['dayofweek'] = births.index.dayofweek
Теперь можно визуализировать динамику рождаемости по дням недели для разных десятилетий:
import matplotlib.pyplot as plt
import matplotlib as mpl
births.pivot_table('births', index='dayofweek',
columns='decade', aggfunc='mean').plot()
plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun'])
plt.ylabel('mean births by day');
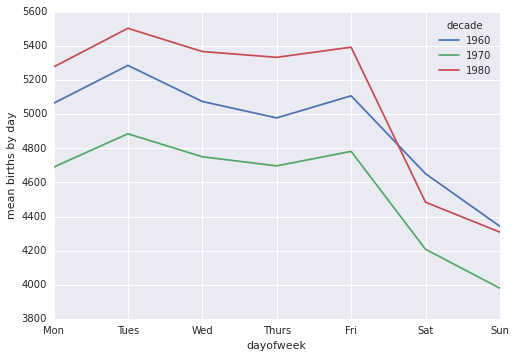
Очевидно, что в будние дни на свет появилось немного больше новорожденных, чем в выходные! Обратите внимание, 1990-е и 2000-е годы отсутствуют, потому что, начиная с 1989 года, в отчетах CDC присутствует только количество новорожденных по месяцам, а не по дням.
Давайте визуализируем еще один интересный показатель – среднее количество новорожденных, приходящееся на каждый день года. Мы можем реализовать это, создав массив дат для определенного года, выбрав при этом високосный год, чтобы учесть 29-е февраля.
# Choose a leap year to display births by date dates = [pd.datetime(2012, month, day) for (month, day) in zip(births['month'], births['day'])]
Теперь сгруппируем данные по дню года и визуализируем результат. Дополнительно выведем на график подписи для тех дней, на которые приходятся некоторые праздники, отмечаемые в США:
# Plot the results
fig, ax = plt.subplots(figsize=(8, 6))
births.pivot_table('births', dates).plot(ax=ax)
# Label the plot
ax.text('2012-1-1', 3950, "New Year's Day")
ax.text('2012-7-4', 4250, "Independence Day", ha='center')
ax.text('2012-9-4', 4850, "Labor Day", ha='center')
ax.text('2012-10-31', 4600, "Halloween", ha='right')
ax.text('2012-11-25', 4450, "Thanksgiving", ha='center')
ax.text('2012-12-25', 3800, "Christmas", ha='right')
ax.set(title='USA births by day of year (1969-1988)',
ylabel='average daily births',
xlim=('2011-12-20','2013-1-10'),
ylim=(3700, 5400));
# Format the x axis with centered month labels
ax.xaxis.set_major_locator(mpl.dates.MonthLocator())
ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=15))
ax.xaxis.set_major_formatter(plt.NullFormatter())
ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter('%h'));
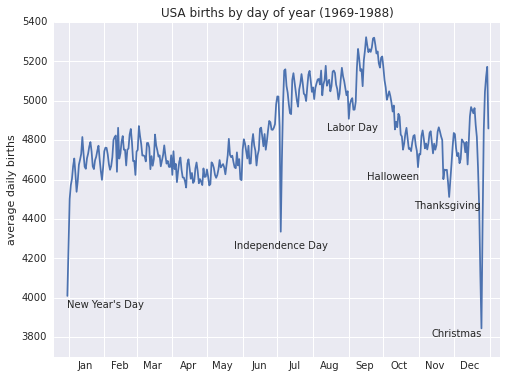
Низкая рождаемость в праздничные дни впечатляет, но это скорее результат выбора даты для плановых или вынужденных родов, чем следствие каких-либо глубоких психосоматических причин.
Эта небольшая статья должна дать вам хорошее представление о том, как разнообразные инструменты из библиотеки Pandas могут быть объединены вместе и использованы для извлечения информации из различных наборов данных. В следующих статьях мы рассмотрим более сложные подходы к анализу этих и других данных!
По материалам: O’Reilly
Подскажите пожалуйста, почему последний график подписан USA births by day of year (1969-1988), если мы используем данные только за 2012 год?
А нет, все верно, извините.