
Конспект выступления Сергея Марина, руководителя службы разработки продуктов Big Data компании «Билайн», на встрече «Фестиваль данных» в рамках выставки высоких технологий SMIT.
В этом году Gartner в своем исследовании Hype Cycle, где они показывают тренды технологий, исчезла Big Data. Многие об этом говорили. По-сути, аналитики Gartner официально заявили, что Big Data больше нет.
Наша точка зрения такова. Big Data — это некий маркетинговый термин. Понятно, что не потому, что данные стали объемные, стало все замечательно. Данных стало много, это так, но важнее то, что данные появились везде — в телематике, в медицине, в рекламе. Тренд, независомо от того, называем ли мы его Big Data или нет, состоит в том, умеем ли мы эти данные собирать и обрабатывать. В приниципе, речь идет об анализе данных. Но Big Data звучит «круче», чем «анализ данных», поэтому все предпочитают использовать понятие Big Data.
Конечно, есть классы задач, где используются действительно большие объемы данных. Тем не менее, это все то же развитие идей машинного обучения.
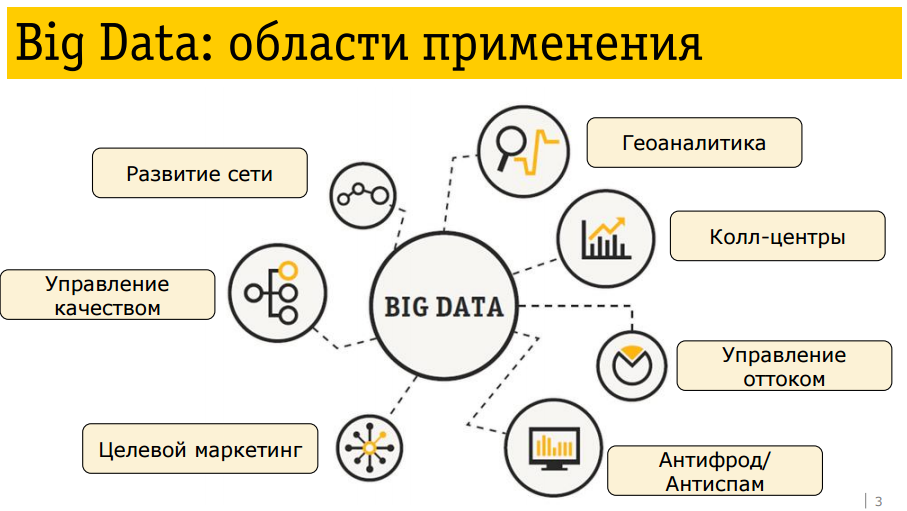
То, чем мы занимаемся в Билайне — это в большинстве случаев анализ Big Data. Поскольку анализируемых данных действительно много. Абонентская база — более 50 млн абонентов. По каждому абоненту есть целый набор анализируемых параметров. Если все объединить, получается петабайт информации, которую нам предстоит обрабатывать.
Зачем мы вообще этим занимаемся? Сейчас это уже вполне очевидно, а вот пару лет назад действительно такой вопрос возникал. Это настоящее «золото», которым компания располагает и которое поддается монетизации. Под монетизацией я понимаю, например, возможность разработать какой-то продукт, который будет привлекателен для клиента, предложить его таргетированному клиенту. Это из серии — клиенту хорошо и нам хорошо.
Важно, что речь идет не только об анализе собственных (внутренних) данных компании. Нам интересно анализировать также внешние данные.
Начнем с нас. Для чего мы используем анализ данных?

Почему это Big Data? Потому, что мы знаем многое о каждом клиенте. Некоторые вещи с задержкой в пару секунд, иногда с задержкой до 15 минут. Фактически, на любое событие с клиентом можем реагировать. Например, клиент приехал в аэропорт, клиент подключил смартфон, клиент вернулся из роуминга. Есть понятие «клиентского пути», который проходит клиент в течение всего цикла пользования нашими услугами.
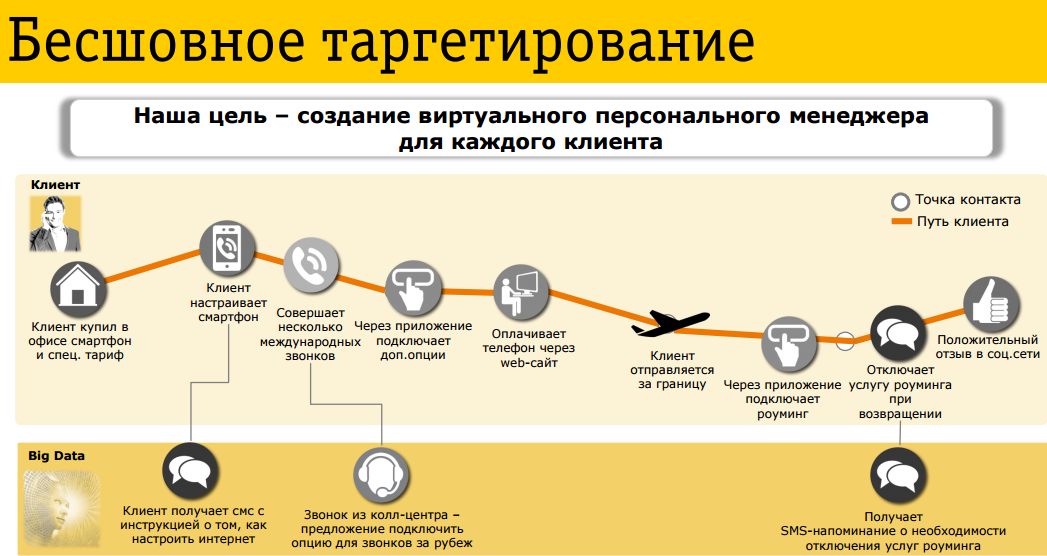
Если система установила, что клиент направляется за границу, ему уместно предложить подключение услуги роуминга. Если он, напротив, вернулся из-за границы, стоит ему напомнить, что имеет смысл отключить какие-то опции, которые теперь стали ненужными.
Если клиент приобрел смартфон, ему можно предложить подключить мобильный интернет.
Это простые задачки, здесь не требуется использование механизмов типа «машинного обучения». Просто триггерная активность, которая, тем не менее, делается в реальном времени на большом объеме данных.
При таком подходе нужно стремиться к предельному виду персонализации.
Другая тема — наши семейные тарифы линейки ВСЁ! Здесь вопрос в том, как эти семьи отыскать? Это решаемая задача. Это так называемая графовая задача.
Какие еще интересные направления есть в аналитике данных в Билайн?
Управление оттоком. Тема не новая. Иногда это машинное обучение на обучающей выборке. У нас есть выборка клиентов, которые ушли. Можно ретроспективно изучить их на предмет корреляции между собой и, выявив такие корреляции, проверить базу для того, чтобы спрогнозировать, чей уход следует ожидать. Здесь тоже Big Data — если раньше было порядка 50 параметров, описывающих клиента, то сейчас зачастую — это около тысячи параметров.
Колл-центры. Здесь также предсказания очень важны и их можно генерировать. Как правило, перед тем, как происходит какой-то звонок от клиента в колл-центр, у клиента происходит какое-то «событие». Это может быть, например, обрыв связи и невозможность ее установить. Если мы наблюдаем, что между таким событием и звонками в колл-центр есть корреляция, то можно выделить группу клиентов «собирающихся звонить» в колл-центр. Уместно таким клиентам разослать превентивно SMS, в который проинформировать, что компания в курсе аварии, что меры принимаются, назвать прогнозное время восстановления услуги, извиниться. На выходе получаем существенное снижение нагрузки на контактный центр.
Про геоаналитику еще поговорим, это очень важное, интересное направление.
Управление фродом. Возможно не все знают, что такое «фрод» по-отношению к оператору связи. На самом деле, компания от этого страдает, поскольку есть «нехорошие люди», которые покупают SIM-карты и начинают через них быстро прогонять огромный объем трафика. Не буду рассказывать, по понятным причинам, как это организовано. Важно, что мы должны уметь очень быстро ловить такие события, чтобы оперативно предпринимать соответствующие действия. Поскольку если не среагировать быстро, никакой борьбы с фродерами не получится, поскольку карта очень быстро изымается из обращения. Мы умеем быстро замечать и реагировать.

Есть одна тема, интересная наверное всем, кто интересуется темой Big Data. Это «графовые модели».
Мы проанализировали данные компании для проверки известной «теории шести рукопожатий». У нас получилось, что любой клиент Билайн связан с любым другим клиентом Билайн всего через 4 «рукопожатия».
У нас есть задача, связанная с так называемым «внутренним оттоком». Это ситация, когда клиент приходит в офис продаж или к агенту, и ему продают новую SIM-ку с новым номером. Как известно, не все люди чувствительны к смене телефонного номера, зато многие чувствительны к тому, что могут получить новый, более выгодный тариф. Почему это делает агент? Потому что у него план продажи новых номеров, у него комиссия за такие продажи, ему нужно делать план. Чем это плохо для компании? Тем, что она платит агенту эту комиссию по-сути за уже имевшегося клиента.
Соответственно, такого клиента нужно найти. А агенту сказать, что у вас реальные продажи — 30%, а остальные 70% — это не то, что требуется. Каким «боком» здесь графовая модель участвует? Таким, что мы анализируем профиль звонков нового клиента на предмет корреляции с профилями звонков старых клиентов. И если они статистически совпадают, мы делаем обоснованное предположение о том, что это один человек. Далее считаем общее количество и вычисляем процент внутреннего оттока в продажах.
Близкая тема — это мультидевайсы. Сейчас у многих две SIM-карты. Понятно, что если складывать абонентские базы «большой четверки», даже без региональных операторов, то получаем больше населения России. Очевидно, что у большинства людей более 1 SIM-карты. Как считать не в SIM-картах, а в людях? Эту задачу приходится решать всем операторам сотовой связи. SIM-карты считать легко, они «светятся» в биллинге. Задача также решается, как графовая, по профилю звонков.
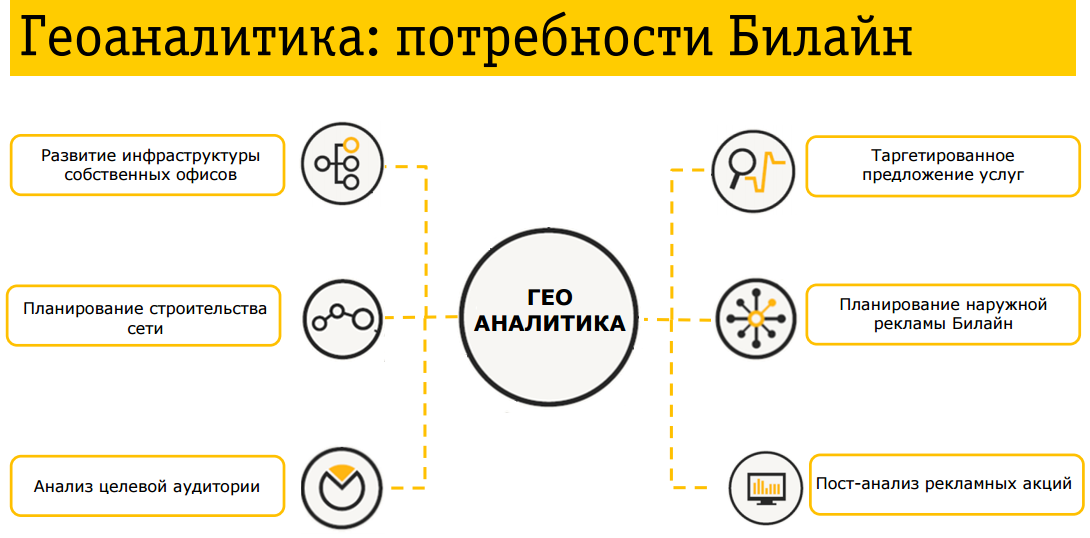
Геоаналитика. Одна из очевидных задач оператора в области Big Data. Но при этом вовсе не тривиальная. Одни люди даже не думают, что это вообще возможно. Другие уверены, что пока у них в кармане лежит сотовый телефон, их местоположение известно с высокой точностью. Между тем, если, например, телефон старый, то о местоположении абонента известно только то, в каком секторе сети сотовой связи он находится. На выходе в этом случае данные с точностью 300-500 метров удаления от антенны в треугольнике с углом раскрыва 120 градусов. Причем данные о местоположении обновляются не в реальном времени, а, в основном, по факту каких-то действий — вы отправили SMS, приняли SMS, получили вызов, сделали вызов…
Ситуация со смартфонами чуть иная, они еще периодически в интернет выходят. Еще лучше смартфоны 4G/LTE, где на уровне протокола предусмотрена возможность постоянного съема геоданных.
В целом задача трудная, но интересная. Приходится прогнозировать положение абонента, поскольку она не известно нам в точности.
Зачем это нужно? Для выбора местоположения офисов розничных продаж. Они должны размещаться там, где есть существенный трафик абонентов компании. То же и в отношении развития сети — местоположение базовых станций должно выбираться с учетом потенциального спроса клиентов на трафик в данной точке.
И, конечно, анонимизированные данные могут быть использованы, например, в целях планирования развития города. Почему планирование города — это актуально?

Картинка, конечно, шутливая. Но если реально смотреть на вещи… Есть перепись населения, которая проводится достаточно редко. И есть такой город, как Москва, в котором вы представляете, как динамично все меняется. Поэтому статистические данные очень часто значительно отличаются от реальных.
Если мы захотим еще глубже сегментировать. На «проживающее население», «работающее население» и т.п.
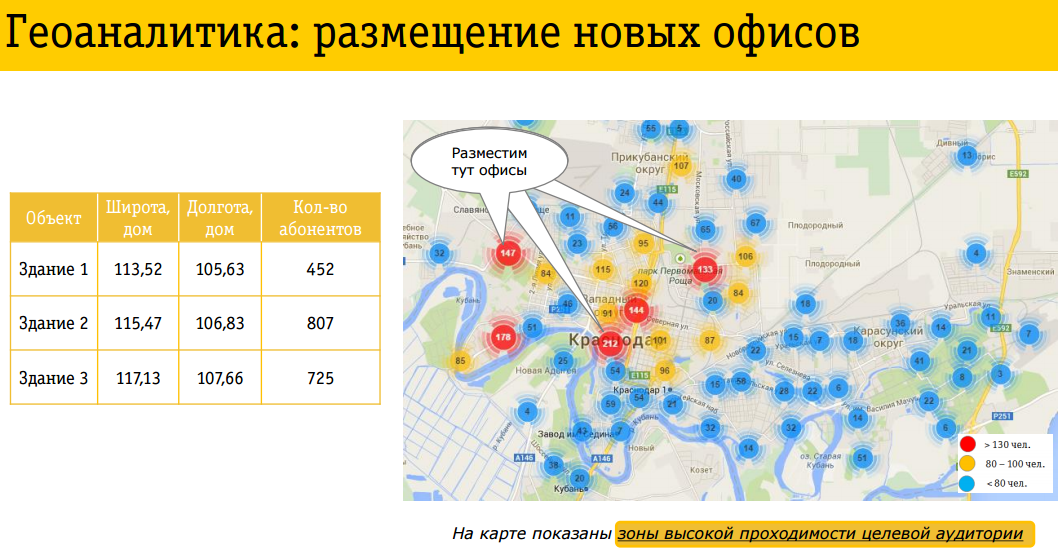
Например, нужно посчитать, какой процент населения каждый день покидает заданный район. Это реальная задача. Важно, чтобы район покидал процент населения, не выше, чем ХХ, поскольку если будет выше, то имеющаяся дорожная инфраструктура не будет справляться. Понятно, что уже во многих районах не справляется. Спрашивается, как отслеживать этот процент? Можно, конечно, на транспортных магистралях поставить счетчиков, которые будут считать машины… что-то не очень это делают, вероятно, это достаточно дорого и не слишком точно.
Поэтому геоаналитика операторов сотовой связи сейчас очень востребована госструктурами, которые на ее основе планируют развитие города.
Мы с этого в свое время начинали пару лет назад. Тогда еще не зная, как это делать, какие данные нужно собирать. Сейчас значительно продвинулись, есть стандартные отчеты, которые мы предоставляем для использования госструктурами. А также используем в собственной деятельности.
Вернемся к тому, как именно мы делаем аналитику данных.
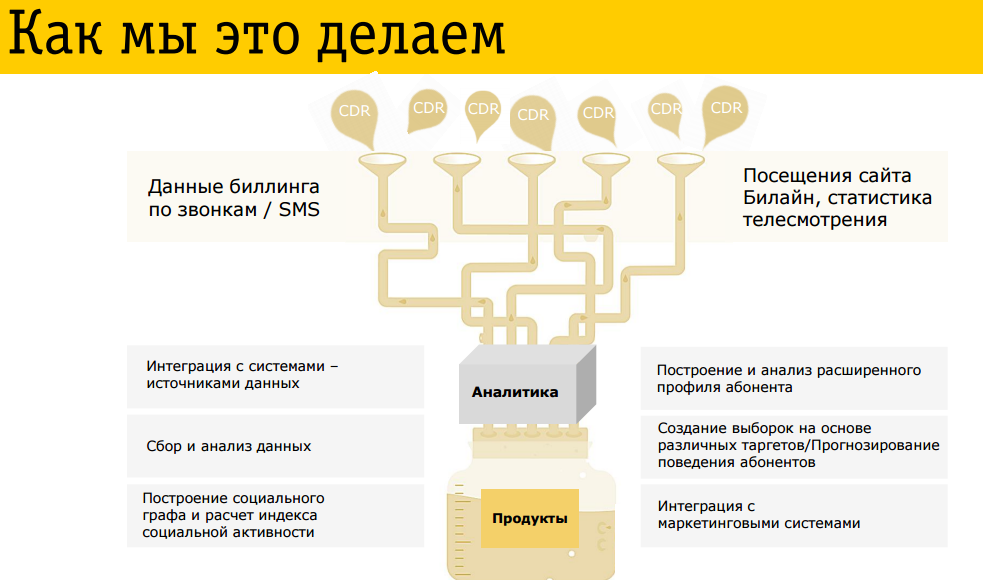
У нас есть большой набор данных, поступающих с различных систем. Они складываются в большой кластер Hadoop. У нас есть традиционное хранение в Oracle, но все новые Big Data мы складываем в Hadoop. Поверх работает аналитика. Она двух типов. Графоаналитика больших данных, а неграфовая — это, скорее, small data, когда берется некая «обучающая выборка» (small data) на основе которой с помощью методов машинного обучения строится компьютерная модель. И затем эту модель распространяем на весь кластер. По факту, на работу со Small data уходит больше времени, чем на работу с Big Data.
Стек используемых технологий — здесь нет ничего «революционного» для занимающихся темой Big Data.

Когда говорят о машинном обучении, на практике уже не особенно интересно, как именно это делается. Инструментарий вполне понятен. Куда интереснее вопрос о том, кто этим занимается. Кто такой этот современный Data Scientist?

Этих людей мало. Их мало где учат. И в основном они сконцентрированы не в бизнесе, а в научных заведениях. Разве что есть интернет-компании, как тот же Яндекс, где их сравнительно (относительно) много. В любом случае поиск таких людей — это отдельная задача. Не в последнюю очередь для решения этой задачи мы и запустили Школу данных.
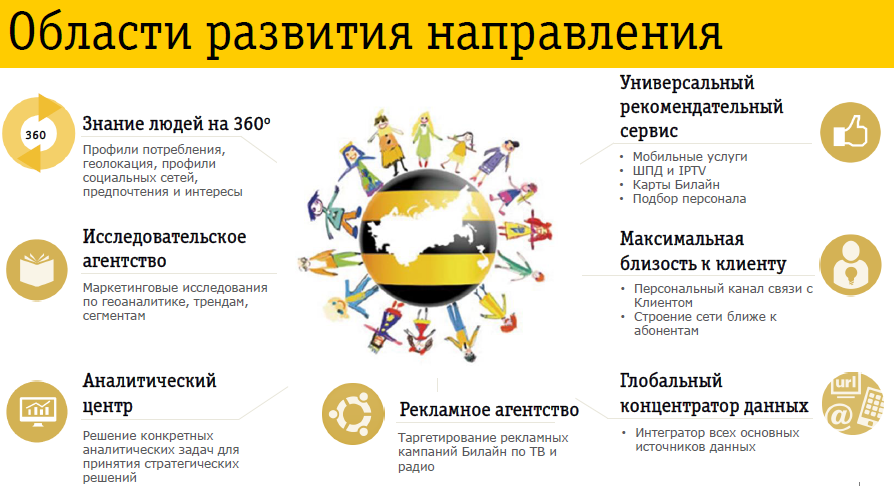
Как я уже говорил, мы не хотим заниматься анализом только собственных данных. На картинке показано, как можно развивать направление анализа данных, объединяя собственные данные компании и внешние данные, которые можно получить. Это общая схема, по которой развиваемся не только мы, но и многие другие участники рынка Big Data.

Людям, занимающимся темой машинного обучения, это уже вполне ясно, другим, возможно, менее понятно. Очень часто встречающаяся задача — заказчик просит определить пол абонента на основе данных о телефонной активности абонента. Исходно задача кажется очень сложной — те паспортные данные, которые есть в базе, зачастую далеко не соответствуют реальному положению дел. Аппарат часто зарегистрирован на одного члена семьи, а пользуется им совсем другой человек. Особенно частой является эта ситуация тогда, когда телефоном пользуется ребенок. В итоге рассуждать о поле пользователя на основе только базы контрактов можно лишь с малой степенью достоверности.
Какие еще идеи могут возникнуть при решении задачи определения пола? Есть ли корреляция со средней продолжительностью вызовов, например? Заказчик, как правило, сам придумывает набор из нескольких параметров — до десятка. Далее мы должны с этими данными и идеями работать. Это не лучший вариант.
Машинное обучение — это когда берется большой набор параметров, более сотни и с ними начинается работа с целью выявления корреляций. Выгружаются реальные данные. Строятся соответствующие модели. Это одна из задач моделирования, с которыми мы работаем.