

Потрясающий вид из особняка в Имеровигли (Греция), который можно арендовать на Airbnb
Введение
Дата-ориентированные инструменты всегда были важной частью сервиса Airbnb. Однако их реализация требует больших затрат. Например, персональное ранжирование результатов поиска позволяет гостям быстрее находить дома, а интеллектуальное ценообразование позволяет хозяевам домов устанавливать конкурентные цены в соответствии с текущим спросом и предложением. Чтобы эти возможности стали доступны пользователям, data scientist’ам и инженерам пришлось проделать большую работу.
Последние усовершенствования в инфраструктуре машинного обучения Airbnb позволили существенно снизить затраты на ввод новых моделей в эксплуатацию. Например, наша команда ML Infra создала глобальный репозиторий признаков, благодаря которому все сотрудники получили доступ к высококачественным проверенным признакам, пригодным для многократного использования и позволяющим создавать эффективные модели. Data scientist’ы начали применять в своих рабочих процессах инструменты автоматизированного машинного обучения (AutoML), чтобы ускорить процесс оценивания и выбора моделей. Кроме того, команда ML Infra разработала новый фреймворк, который автоматически преобразует блокноты Jupyter (Jupyter notebook) в конвейеры Airflow (Airflow pipeline).
В этой статье я расскажу, как применение описанных выше инструментов позволяет ускорить процесс моделирования и снизить общие затраты на разработку. В качестве примера мы рассмотрим процесс разработки LTV-моделей для прогнозирования дохода от аренды домов на Airbnb.
Что такое LTV?
Пожизненная ценность клиента (customer lifetime value, LTV) – это распространенная показатель, применяемый в сфере электронной коммерции. Эта величина представляет собой прогнозируемый доход от сотрудничества с клиентом в пределах фиксированного временного горизонта.
Такие компании, как Spotify и Netflix, обычно используют LTV для принятия решений относительно ценообразования, в частности, для формирования стоимости подписки. Airbnb применяет LTV, чтобы более эффективно распределять бюджет по различным маркетинговым каналам, вычислять более точные предложения цены на основе ключевых слов и более эффективно сегментировать объявления.
Несмотря на то, что мы можем использовать исторические данные, чтобы вычислить исторический доход от объявлений, уже присутствующих в базе, мы сделали шаг вперед, стремясь предсказать LTV новых объявлений с помощью машинного обучения.
Рабочий процесс моделирования LTV с помощью машинного обучения
Data scientist’ы привыкли к таким подзадачам машинного обучения, как инженерия признаков, прототипирование и выбор моделей. Однако, чтобы ввести прототип модели в эксплуатацию, обычно требуются навыки в области инженерии данных (data engineering), которые могут отсутствовать у data scientist’ов.
К счастью, в Airbnb у нас есть инструменты, позволяющие абстрагировать инженерные задачи, выполняемые при развертывании моделей. На самом деле, без этих удивительных инструментов ввод моделей в эксплуатацию был бы практически невозможен.
Далее мы рассмотрим 4 основные задачи и инструменты, применяемые для их решения:
-
Инженерия признаков: создание информативных признаков.
-
Прототипирование и обучение: обучение прототипа модели.
-
Выбор модели: выбор модели и ее настройка.
-
Ввод в эксплуатацию: развертывание выбранного прототипа модели.
Инженерия признаков
Инструмент: Zipline – внутренний репозиторий признаков Airbnb.
Одним из первых этапов любого проекта в сфере машинного обучения с учителем является создание информативных признаков, коррелирующих с выбранной целевой переменной. Этот процесс называется инженерией признаков (feature engineering). Например, в задаче прогнозирования LTV признаком может быть процент доступных дат из следующих 180, или относительная цена по сравнению с подобными домами из того же сегмента.
В Airbnb инженерия признаков, как правило, подразумевает выполнение запросов к Hive, чтобы создать признаки с нуля. Эта работа утомительна и отнимает много времени, поскольку требует специальных знаний в предметной области и понимание бизнес-логики. Как следствие, процедуры создания признаков являются специфичными для конкретной задачи и зачастую непригодны для повторного использования. Чтобы решить эту проблему, мы создали Zipline – репозиторий признаков для машинного обучения, содержащий признаки различной природы, характеризующие хозяина, гостя, объявление, сегмент рынка и др.
Краудсорсинговая природа этого внутреннего инструмента, позволяет data scientist’ам использовать широкое разнообразие высококачественных проверенных признаков, разработанных другими data scientist’ами в рамках предыдущих проектов. Если необходимый признак отсутствует, пользователь может создать его самостоятельно с помощью файла конфигурации:
source: {
type: hive
query:»»»
SELECT
id_listing as listing
, dim_city as city
, dim_country as country
, dim_is_active as is_active
, CONCAT(ds, ‘ 23:59:59.999’) as ts
FROM
core_data.dim_listings
WHERE
ds BETWEEN ‘{{ start_date }}’ AND ‘{{ end_date }}’
«»»
dependencies: [core_data.dim_listings]
is_snapshot: true
start_date: 2010-01-01
}
features: {
city: «City in which the listing is located.»
country: «Country in which the listing is located.»
is_active: «If the listing is active as of the date partition.»
}
Если для создания обучающего набора данных требуется несколько признаков, Zipline автоматически выполнит интеллектуальное объединение и сформирует набор данных. В задаче моделирования LTV мы использовали существующие признаки, доступные в Zipline, а также несколько новых признаков. В итоге в нашей модели было использовано более 150 признаков:
-
Местоположение: страна, район и другие географические признаки.
-
Цена: цена за ночь, плата за уборку, относительная цена по сравнению с подобными объявлениями.
-
Доступность: количество доступных ночей; процент ночей, заблокированных вручную.
-
Бронирование: количество забронированных ночей за последние X суток.
-
Качество: оценки гостей, количество отзывов, преимущества.
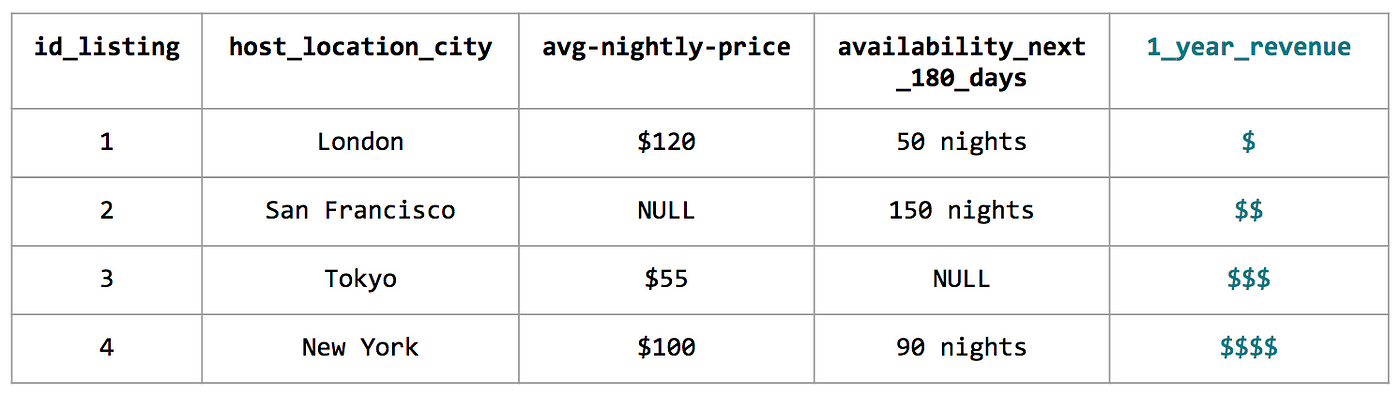
Пример обучающего набора данных
Имея в распоряжении признаки и целевую переменную, мы можем приступить к обучению модели.
Прототипирование и обучение
Инструмент: Python-библиотека для машинного обучения scikit-learn.
Обычно перед обучением модели необходимо выполнить дополнительную обработку данных. В частности, в нашем примере потребуются следующие операции:
-
Заполнение отсутствующих значений. Необходимо проверить, отсутствуют ли какие-либо значения в данных. Кроме того, необходимо определить, является отсутствие данных случайным или системным. Если явление системное, необходимо выяснить причину, если случайное – необходимо заполнить отсутствующие значения.
-
Кодирование категорийных переменных. Мы не можем использовать категории в исходном виде, поскольку алгоритмы, как правило, не работают со строками. Если количество категорий невелико, мы можем применить прямой унитарный код (one-hot encoding). Если же мы имеем дело с большим количеством категорий, можно применить порядковое кодирование (ordinal encoding) или кодирование на основе частоты (encoding by frequency count) каждой категории.
На данном этапе мы точно не знаем, каким должен быть оптимальный набор признаков, поэтому очень важно написать код, позволяющий быстро тестировать различные варианты. Конвейеры (pipeline), доступные в различных библиотеках, таких как scikit-learn и Spark, является очень удобным инструментом для прототипирования. Конвейер представляет собой высокоуровневую схему, которая описывает последовательность преобразований данных и обучаемую модель. Ниже представлен фрагмент конвейера, использованного для разработки нашей LTV-модели:
transforms = []
transforms.append(
(‘select_binary’, ColumnSelector(features=binary))
)
transforms.append(
(‘numeric’, ExtendedPipeline([
(‘select’, ColumnSelector(features=numeric)),
(‘impute’, Imputer(missing_values=’NaN’, strategy=’mean’, axis=0)),
]))
)
for field in categorical:
transforms.append(
(field, ExtendedPipeline([
(‘select’, ColumnSelector(features=[field])),
(‘encode’, OrdinalEncoder(min_support=10))
])
)
)
features = FeatureUnion(transforms)
Мы используем конвейеры, чтобы задать необходимые преобразования для различных типов признаков: бинарных, категорийных и числовых. FeatureUnion в последней строке объединяет столбцы признаков и формирует итоговый обучающий набор данных.
Преимущество использования конвейеров при написании прототипов заключается в том, что этот подход позволяет абстрагировать кропотливые преобразования данных. Применение конвейеров гарантирует, что комплекс преобразований данных будет выполняться единообразно, как на этапе разработки и тестирования прототипа, так и на этапе его введения в эксплуатацию.
Кроме того, после серии преобразований данных мы можем добавить в конвейер алгоритм машинного обучения. Тестируя с помощью конвейера различные алгоритмы, мы получаем возможность выбрать наилучшую модель с минимальной ошибкой прогноза.
Выбор модели
Инструмент: различные фреймворки для автоматизированного машинного обучения (AutoML).
Как мы уже говорили, наша задача заключается в том, чтобы выбрать наилучший прототип модели для введения в эксплуатацию. Чтобы принять это решение, необходимо найти компромисс между интерпретируемостью модели и ее сложностью. Например, разреженная линейная модель очень хорошо интерпретируется, но при этом является недостаточно сложной, чтобы обеспечить высокую точность. С другой стороны, модель на основе деревьев решений может быть достаточно сложной, чтобы учесть нелинейные закономерности, но ее интерпретация может вызвать затруднения. Это явление известно как компромисс между смещением и дисперсией (bias-variance trade-off).
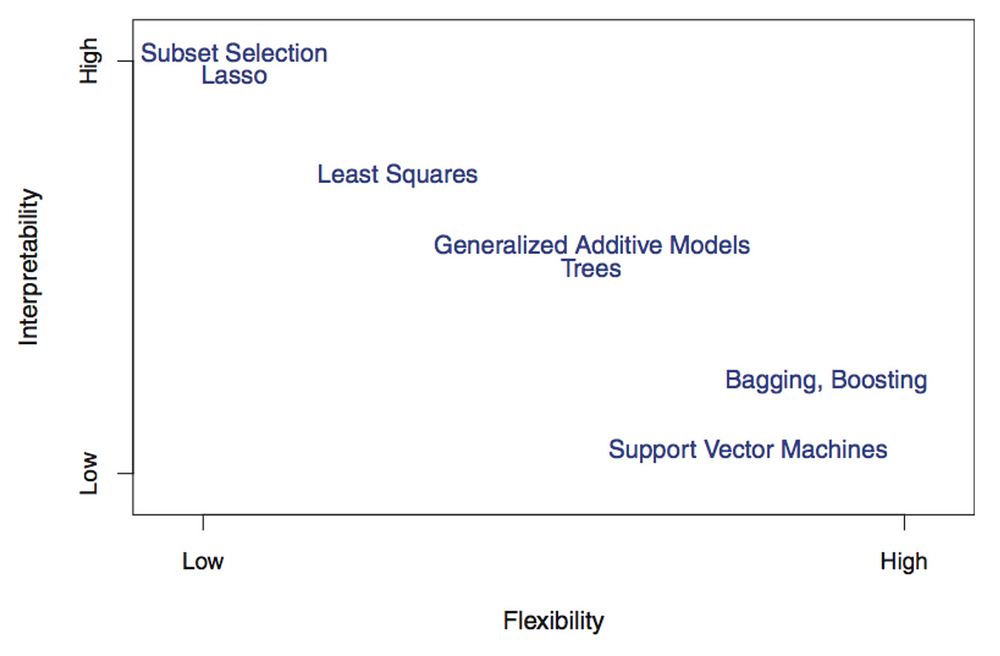
Рисунок из книги «Введение в статистическое обучение с примерами на языке R» (Джеймс, Уиттон, Хасти, Тибширани) («An Introduction to Statistical Learning: with Applications in R» (James, Witten, Hastie, Tibshirani))
Модель, применяемая для решения задач в области страхования и кредитного скоринга, должна быть хорошо интерпретируема, поскольку очень важно, чтобы модель не допускала случайной дискриминации некоторых клиентов. С другой стороны, если речь идет о модели для классификации изображений, здесь намного важнее точность, а не интерпретируемость.
Стремясь ускорить трудоемкий процесс выбора модели, мы экспериментировали с различными инструментами для автоматизированного машинного обучения (AutoML). С помощью этих инструментов мы протестировали большое количество различных моделей и отобрали лучшие из них. Например, мы выяснили, что результаты моделей на основе экстремального градиентного бустинга (extreme gradient boosting, XGBoost) существенно превосходят результаты эталонных моделей, таких как гребневая регрессия (ridge regression) и одиночные деревья решений (single decision tree).
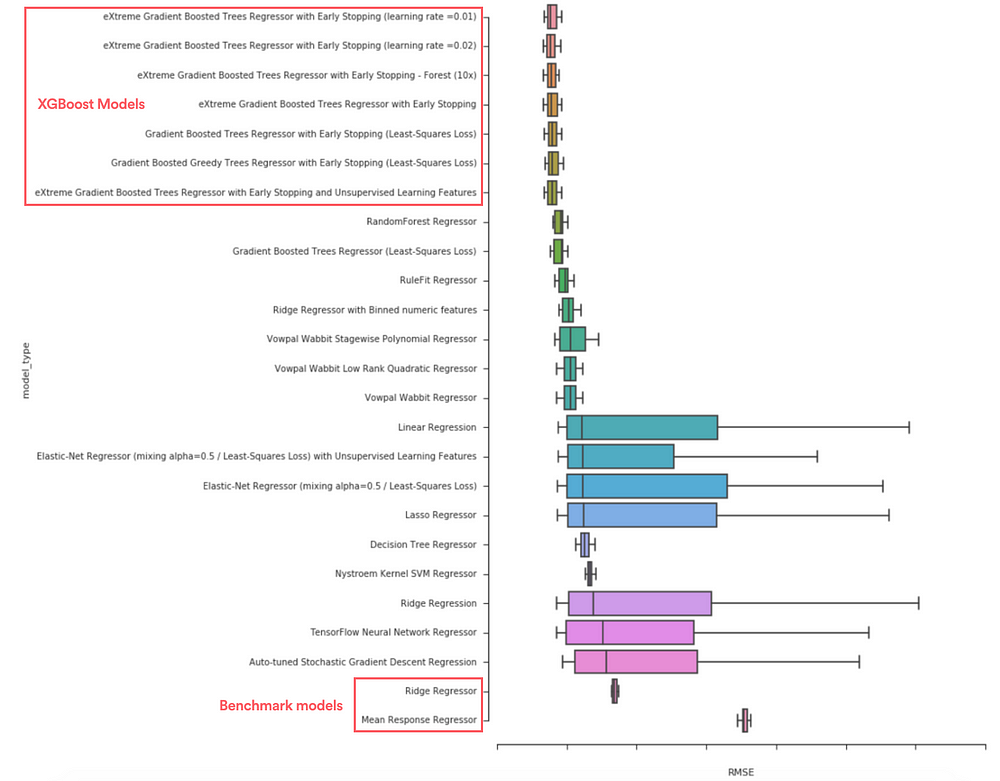
Сравнение среднеквадратической ошибки (RMSE) прогнозов позволяет выбрать наилучшую модель
Принимая во внимание то, что наша основная цель заключалась в точном предсказании дохода от объявлений, мы выбрали модель на основе XGBoost, обеспечивающую высокую точность, хотя ее непросто интерпретировать.
Ввод в эксплуатацию
Инструмент: ML Automator – фреймворк для конвертирования блокнотов, разработанный в Airbnb
Этап разработки прототипа модели и этап фактической эксплуатации модели существенно отличаются. На этапе эксплуатации могут возникать специфичные задачи, в частности: периодическое повторное обучение; прогнозирование для большого количества примеров; мониторинг эффективности модели во времени.
В Airbnb мы создали фреймворк под названием ML Automator, который автоматически преобразует блокноты Jupyter в конвейеры Airflow. Этот фреймворк предназначен специально для data scientist’ов, которые прототипируют на Python и стремятся вводить свои модели в эксплуатацию, обладая ограниченным опытом в области инженерии данных.
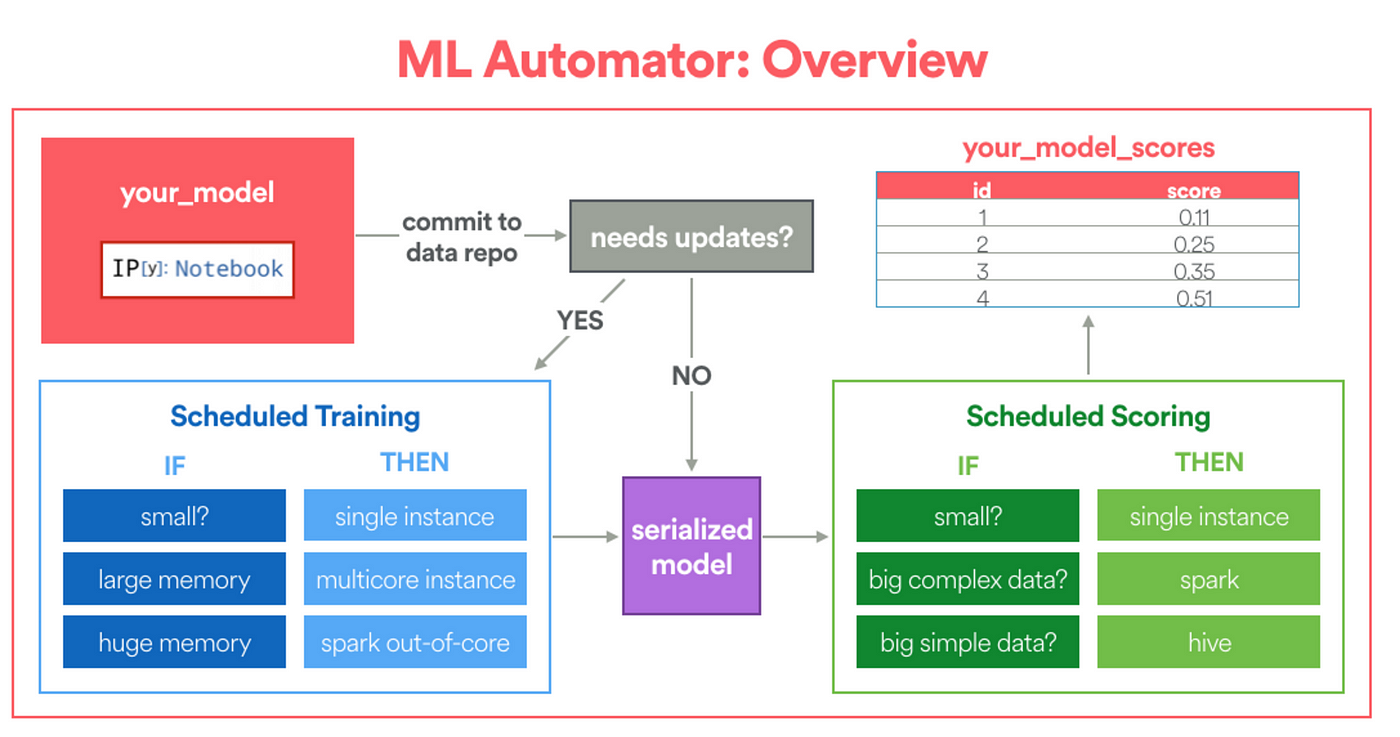
Упрощенная схема фреймворка ML Automator
Чтобы использовать фреймворк, пользователь должен указать следующее:
-
Конфигурацию модели в блокноте. Конфигурация модели сообщает фреймворку, где находятся обучающие данные, какой объем вычислительных ресурсов необходим для обучения, как будут вычислены оценки.
-
Специальные функции fit и transform. Функция fit определяет, как будет выполняться обучение. Функция transform будет обернута, как пользовательская функция Python (Python UDF) для распределенного оценивания (если требуется).
Ниже представлен фрагмент кода, демонстрирующий определения функций fit и transform в нашей LTV-модели. Функция fit сообщает фреймворку, что будет обучена модель на основе XGBoost, и выполнены преобразования данных на основе созданного ранее конвейера.
def fit(X_train, y_train):
import multiprocessing
from ml_helpers.sklearn_extensions import DenseMatrixConverter
from ml_helpers.data import split_records
from xgboost import XGBRegressor
global model
model = {}
n_subset = N_EXAMPLES
X_subset = {k: v[:n_subset] for k, v in X_train.iteritems()}
model[‘transformations’] = ExtendedPipeline([
(‘features’, features),
(‘densify’, DenseMatrixConverter()),
]).fit(X_subset)
# apply transforms in parallel
Xt = model[‘transformations’].transform_parallel(X_train)
# fit the model in parallel
model[‘regressor’] = XGBRegressor().fit(Xt, y_train)
def transform(X):
# return dictionary
global model
Xt = model[‘transformations’].transform(X)
return {‘score’: model[‘regressor’].predict(Xt)}
Обработав блокнот, ML Automator обернет обученную модель в пользовательскую функцию Python (Python UDF) и создаст конвейер Airflow, показанный на рисунке ниже. Все задачи, связанные с инженерией данных, такие как сериализация данных, планирование периодического повторного обучения и распределенное оценивание, инкапсулированы в ежедневном пакетном задании. Таким образом, данный фреймворк существенно уменьшает затраты, облегчая разработку и развертывание моделей для data scientist’ов, как будто в команде с ними работает дата-инженер, выполняющий ввод моделей в эксплуатацию!
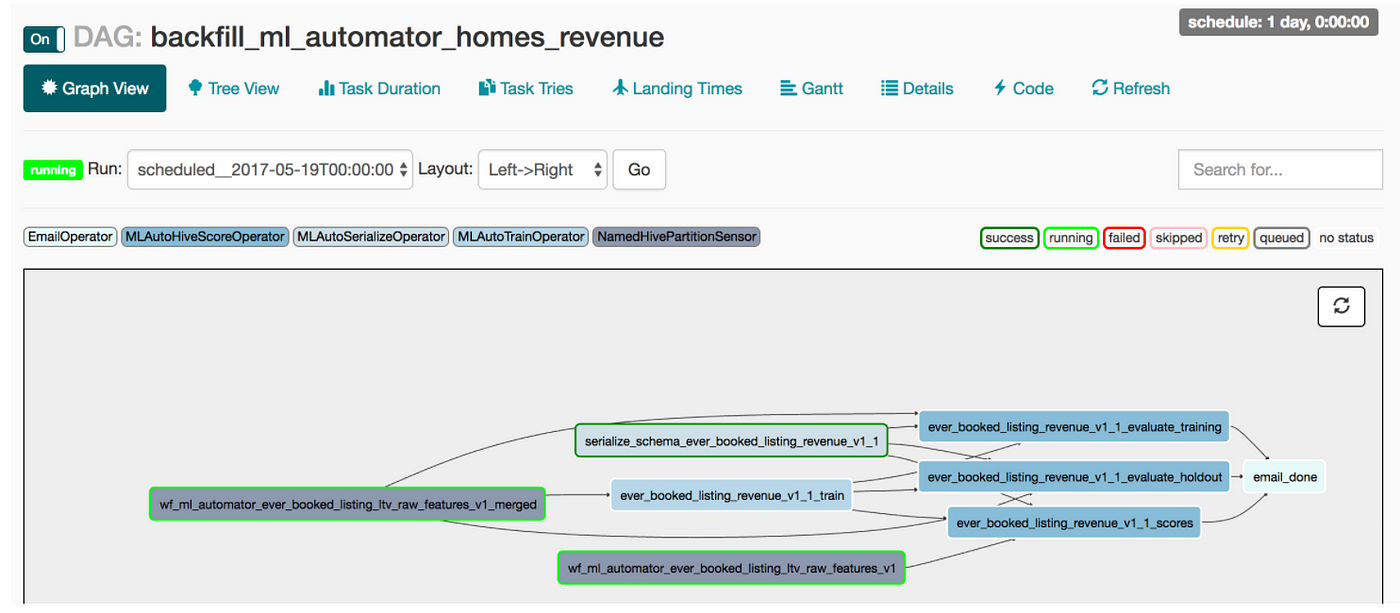
Граф рабочего процесса Airflow для нашей LTV-модели
Следует отметить, что кроме аспектов, связанных с вводом моделей в эксплуатацию, существуют и другие важные аспекты, такие как мониторинг эффективности моделей во времени, использование преимуществ эластичной вычислительной среды для моделирования, которые не рассматриваются в этой статье. Будьте уверены, наша команда активно работает также и в этих направлениях.
Извлеченные уроки и перспективы
В течение нескольких последних месяцев data scientist’ы тесно сотрудничали с командой ML Infra. В результате возникло множество интересных идей и концепций. Мы верим, что созданные нами инструменты позволят реализовать новую парадигму разработки моделей в Airbnb.
-
Во-первых, существенно уменьшаются затраты на разработку моделей. Благодаря совместному использованию преимуществ каждого инструмента (Zipline для инженерии признаков, конвейеры для прототипирования, AutoML для тестирования и выбора моделей, ML Automator для ввода в эксплуатацию) нам удалось существенно ускорить цикл разработки.
-
Во-вторых, дизайн на основе блокнотов понижает порог вхождения. Data scientist’ы, незнакомые с фреймворком, получают в свое распоряжение массу примеров из реальной практики. Блокноты, используемые в реальных условиях, гарантированно являются корректными и актуальными, при этом их код хорошо документирован. Этот дизайн находит широкую поддержку у новых пользователей.
-
В результате, специалисты получают возможность посвящать больше времени новым идеям. В частности, на момент написания данной статьи, наши команды занимались исследованием таких возможностей, как: прогнозирование вероятности появления помощников хозяина (co-host) для данного объявления, автоматическое выявление объявлений низкого качества и др.
Рассмотренный нами фреймворк и новая парадигма, порожденная им, имеют большое будущее. Благодаря преодолению барьера между прототипированием и вводом в эксплуатацию, data scientist’ы получили возможность контролировать полный цикл разработки проектов машинного обучения. В результате повышается общая эффективность разработки и качество сервиса в целом.