
Если бы я утверждал, что в последнее время человечество стало более эгоистичным, вы бы, скорее всего, назвали меня скрягой, склонным к нытью о «старых добрых временах». Но что, если бы я смог доказать правдивость этого суждения посредством анализа 150 миллиардов слов текста? Несколько десятилетий назад, доказательства в таком масштабе были несбыточной мечтой. Сегодня же 150 миллиардов единиц данных никого не удивят, ведь все сферы — от биологии до лингвистики, от финансов до менеджмента — переживают бум больших данных.
Основная цель применения Big Data — поиск скрытых закономерностей в огромных массивах информации. Генерируют эту информацию пользователи, регистрируясь на сайтах, оставляя посты в социальных сетях, рассчитываясь кредитными картами. Анализ этих данных помогает компаниям прогнозировать спрос на продукты и услуги, предотвращать отток клиентов, налаживать цепочки поставок, повышать эффективность маркетинговых акций и т.д.
Но есть проблема: принято считать, что аналитика всегда гарантирует правильный и точный результат. В этой статье мы поговорим о том, стоит ли слепо доверять каждому из таких результатов.
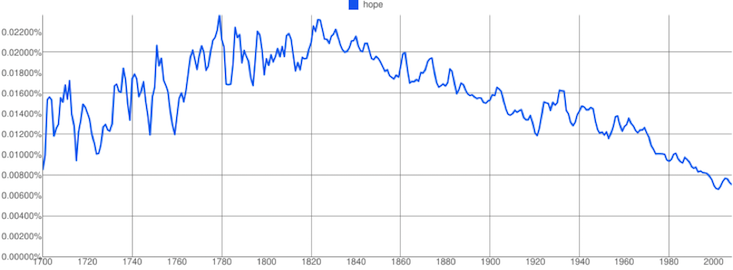
В сфере языка и культуры большие данные «проявили себя» еще в 2011 году, когда Google выпустила инструмент Ngrams. Google Ngrams позволял пользователям искать короткие фразы в базе данных отсканированных книг Google Books (около 4% всех когда-либо опубликованных), чтобы увидеть, как со временем изменилась частота их употребления. С тех пор Google Ngrams стал не только бесконечным источником развлечений, но и кладезем полезной информации для лингвистов, психологов и социологов. Новая технология позволила доказать, что американцы становятся все более эгоцентричными; что человечество забывает прошлое быстрее с каждым годом; что нравственные идеалы исчезают из культурного сознания.
Однако, по мнению экспертов, способ построения базы данных Ngrams имеет свои недостатки, поскольку он не учитывает:
-
тираж (Google Books включает в себя только одну копию каждой книги)
- истинный культурный вес книги («Властелин колец», например, не получает больше влияния, чем, скажем, «Охота на ведьм в Баварии»)
- популярность автора и т.д.
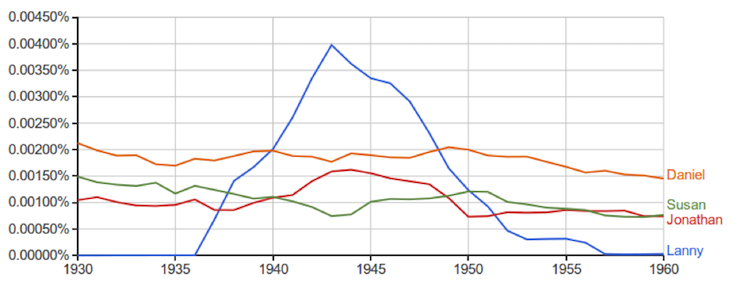
Забавный пример: при помощи Ngrams исследователи выяснили , что в течение 20 лет в 1900-х годах, самым популярным именем для главного персонажа или его брата в английской художественной литературе было имя Лэнни. На самом деле, эти данные отражают, насколько продуктивным (но не обязательно популярным) был автор Аптон Синклер, который выпустил 11 романов о Лэнни Бадде.
Губительно на последовательность и сбалансированность базы данных Ngrams влияет заметное увеличение количества научных статей, начиная с 1960-х годов. Таким образом, сложно поверить, что Google Ngrams точно отражает временные сдвиги в культурной популярности слов.
Даже если не принимать во внимание проблему источников данных, остается вопрос интерпретации. Конечно, частота использования таких слов, как «характер» и «достоинство» может снизиться в течение десятилетий. Но значит ли это, что люди заботятся о нравственности меньше? Вовсе нет. По мнению Теда Андервуда, преподавателя английского языка в Университете штата Иллинойс, Урбана-Шампейн, сама концепция морали или достоинства на рубеже прошлого века, скорее всего, резко отличается от современной, что делает любые выводы в этом русле непрофессиональными.
Вспомним случай с инструментом Google Flu Trends (GFT). Выпущенный в 2008 году, GFT был создан для анализа локации и количества поисковых запросов, вроде «лихорадка» и «кашель», используя их для прогнозирования вспышек инфекции гриппа — на 2 недели раньше госорганов.
Первоначально команда GFT утверждала, что точность результатов — 97 %. Как показала практика, эта цифра была далека от реальности. Весной и летом 2009 года GFT не смог предсказать пандемию свиного гриппа. В результате Google закрыли проект.
Так что же пошло не так? Как и в случае с Ngrams, люди не внимательно отнеслись к источникам и интерпретации данных. Google поиск оказался не самым надежным источником. Инженеры GFT ошиблись с поисковыми терминами, которые могли сигнализировать о предстоящей эпидемии гриппа.
Это не значит, что результаты прогнозов были абсолютно бесполезными. Они дали толчок для других исследователей, которым удалось улучшить алгоритмы прогнозирования. Так, несколько ученых из Колумбийского университета смогли более точно спрогнозировать вспышки гриппа, используя дополнительные исторические данные.
Как сказал знаменитый статистик Джордж Бокс, «все модели некорректны, но некоторые из них полезны».