
Объемы и сложность данных постоянно растут. В результате, существенно увеличивается и их размерность. Для компьютеров это не проблема — в отличие от людей: мы ограничены всего тремя измерениями. Как быть?
Многие реальные наборы данных имеют малую внутреннюю размерность, даже если они вложены в пространство большой размерности.
Представьте, что вы фотографируете панорамный пейзаж, поворачиваясь вокруг своей оси. Мы можем рассматривать каждую фотографию, как точку в 16 000 000-мерном пространстве (при использовании камеры с разрешением 16 мегапикселей). При этом набор фотографий лежит в трехмерном пространстве (рыскание, тангаж, крен). То есть пространство малой размерности вложено в пространство большой размерности сложным нелинейным образом. Эта структура, скрытая в данных, может быть восстановлена только с помощью специальных математических методов.
К ним относится подраздел машинного обучения без учителя под названием множественное обучение (manifold learning) или нелинейное уменьшение размерности (nonlinear dimensionality reduction).
Эта статья — введение в популярный алгоритм уменьшения размерности под названием t-SNE (t-distributed stochastic neighbor embedding, стохастическое вложение соседей с распределением Стьюдента). Разработанный Лоренсом ван дер Маатеном и Джеффри Хинтоном, он был успешно применен ко многим реальным наборам данных.
Мы рассмотрим ключевые математические концепции метода, применяя его к учебному набору данных, содержащему изображения рукописных цифр. В эксперименте будем использовать Python и библиотеку scikit-learn.
Визуализация рукописных цифр
Для начала импортируем библиотеки.
# That's an impressive list of imports.
import numpy as np
from numpy import linalg
from numpy.linalg import norm
from scipy.spatial.distance import squareform, pdist
# We import sklearn.
import sklearn
from sklearn.manifold import TSNE
from sklearn.datasets import load_digits
from sklearn.preprocessing import scale
# We'll hack a bit with the t-SNE code in sklearn 0.15.2.
from sklearn.metrics.pairwise import pairwise_distances
from sklearn.manifold.t_sne import (_joint_probabilities,
_kl_divergence)
from sklearn.utils.extmath import _ravel
# Random state.
RS = 20150101
# We'll use matplotlib for graphics.
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import matplotlib
%matplotlib inline
# We import seaborn to make nice plots.
import seaborn as sns
sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
# We'll generate an animation with matplotlib and moviepy.
from moviepy.video.io.bindings import mplfig_to_npimage
import moviepy.editor as mpy
Теперь загрузим классический набор данных, содержащий рукописные цифры. Он состоит из 1797 изображений с разрешением 8 * 8 = 64 пикселя каждое.
digits = load_digits() digits.data.shape
print(digits['DESCR'])
Ниже представлены изображения цифр:
nrows, ncols = 2, 5
plt.figure(figsize=(6,3))
plt.gray()
for i in range(ncols * nrows):
ax = plt.subplot(nrows, ncols, i + 1)
ax.matshow(digits.images[i,...])
plt.xticks([]); plt.yticks([])
plt.title(digits.target[i])
plt.savefig('images/digits-generated.png', dpi=150)
Применим к набору данных алгоритм t-SNE. Благодаря scikit-learn, для этого требуется всего одна строка кода.
# We first reorder the data points according to the handwritten numbers.
X = np.vstack([digits.data[digits.target==i]
for i in range(10)])
y = np.hstack([digits.target[digits.target==i]
for i in range(10)])
digits_proj = TSNE(random_state=RS).fit_transform(X)
Ниже представлена функция, примененная для визуализации преобразованного набора данных. Цвет каждой точки соответствует определенной цифре (безусловно, эта информация не использовалась алгоритмом уменьшения размерности).
def scatter(x, colors):
# We choose a color palette with seaborn.
palette = np.array(sns.color_palette("hls", 10))
# We create a scatter plot.
f = plt.figure(figsize=(8, 8))
ax = plt.subplot(aspect='equal')
sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40,
c=palette[colors.astype(np.int)])
plt.xlim(-25, 25)
plt.ylim(-25, 25)
ax.axis('off')
ax.axis('tight')
# We add the labels for each digit.
txts = []
for i in range(10):
# Position of each label.
xtext, ytext = np.median(x[colors == i, :], axis=0)
txt = ax.text(xtext, ytext, str(i), fontsize=24)
txt.set_path_effects([
PathEffects.Stroke(linewidth=5, foreground="w"),
PathEffects.Normal()])
txts.append(txt)
return f, ax, sc, txts
Получим следующий результат.
scatter(digits_proj, y)
plt.savefig('images/digits_tsne-generated.png', dpi=120)
Мы видим, что изображения, соответствующие различным цифрам, четко разделены на группы.
Математическая база
Давайте разберемся, как работает алгоритм. Сначала дадим несколько определений.
Точка данных (data point) – это точка xi в исходном пространстве данных RD (data space), где D = 64 – размерность (dimensionality) пространства данных. Каждая точка данных – это изображение рукописной цифры. Всего N = 1797 точек данных.
Точка отображения (map point) – это точка yi в пространстве отображения R2 (map space). Это пространство будет содержать целевое представление набора данных. Между точками данных и точками отображения имеет место биекция (bijection): каждая точка отображения представляет одно исходное изображение.
Как нам выбрать расположение точек отображения? Мы хотим сохранить структуру данных. Более конкретно, если две точки данных расположены близко друг к другу, мы хотим, чтобы две соответствующие точки отображения также располагались близко друг к другу. Пусть |xi — xj| – евклидово расстояние между двумя точками данных, а |yi — yj| – расстояние между точками отображения. Сначала определим условное сходство (conditional similarity) для двух точек данных:
Это выражение показывает, насколько точка xj близка к xi, при гауссовом распределении вокруг xi с заданной дисперсией σi2. Дисперсия различна для каждой точки. Она выбирается таким образом, чтобы точки, расположенные в областях с большой плотностью, имели меньшую дисперсию, чем точки, расположенные в областях с малой плотностью. В публикации детально описано, как вычисляется данная дисперсия.
Теперь определим сходство, как симметричный вариант условного сходства:
Получаем матрицу сходства (similarity matrix) для исходного набора данных. Как же выглядит эта матрица?
Матрица сходства
Следующая функция вычисляет сходство с постоянной σ.
def _joint_probabilities_constant_sigma(D, sigma):
P = np.exp(-D**2/2 * sigma**2)
P /= np.sum(P, axis=1)
return P
Затем вычислим сходство при σi, зависящей от точки данных (находится с помощью двоичного поиска (binary search) согласно публикации). Этот алгоритм реализован в функции _joint_probabilities библиотеки scikit-learn.
# Pairwise distances between all data points. D = pairwise_distances(X, squared=True) # Similarity with constant sigma. P_constant = _joint_probabilities_constant_sigma(D, .002) # Similarity with variable sigma. P_binary = _joint_probabilities(D, 30., False) # The output of this function needs to be reshaped to a square matrix. P_binary_s = squareform(P_binary)
Теперь мы можем вывести матрицу расстояний (distance matrix) для точек данных и матрицу сходства при постоянной и переменной дисперсии.
plt.figure(figsize=(12, 4))
pal = sns.light_palette("blue", as_cmap=True)
plt.subplot(131)
plt.imshow(D[::10, ::10], interpolation='none', cmap=pal)
plt.axis('off')
plt.title("Distance matrix", fontdict={'fontsize': 16})
plt.subplot(132)
plt.imshow(P_constant[::10, ::10], interpolation='none', cmap=pal)
plt.axis('off')
plt.title("$p_{j|i}$ (constant $\sigma$)", fontdict={'fontsize': 16})
plt.subplot(133)
plt.imshow(P_binary_s[::10, ::10], interpolation='none', cmap=pal)
plt.axis('off')
plt.title("$p_{j|i}$ (variable $\sigma$)", fontdict={'fontsize': 16})
plt.savefig('images/similarity-generated.png', dpi=120)
Мы уже видим 10 групп данных, соответствующих 10 цифрам.
Давайте также определим матрицу сходства для точек отображения.
Здесь применяется такой же подход, как и для точек данных, но используется другое распределение (распределение Стьюдента с одной степенью свободы (t-Student with one degree of freedom) или распределение Коши (Cauchy distribution) вместо гауссового распределения). Мы подробно обсудим этот выбор ниже.
В то время как матрица сходства для данных (pij) является постоянной, матрица сходства для отображения (qij) зависит от точек отображения. Мы стремимся к тому, чтобы две эти матрицы были максимально близкими. Это будет означать, что сходные точки данных дают сходные точки отображения.
Физическая аналогия
Представим, что все точки отображения соединены пружинами. Жесткость пружины, соединяющей точки i и j, зависит от разности между сходством двух точек данных и сходством двух точек отображения, т.е. pij — qij. Теперь мы позволим системе изменяться согласно законам физики. Если расстояние между двумя точками отображения большое, а между точками данных малое, – точки отображения притягиваются. Если наоборот – точки отображения отталкиваются.
Целевое отображение будет получено при достижении равновесия.
Представленная ниже иллюстрация демонстрирует процесс динамического формирования структуры графа, основанный на аналогичном подходе. Узлы соединены пружинами, и система изменяется согласно законам физики (автор примера – Майк Босток (Mike Bostock).
Алгоритм
Примечательно то, что эта физическая аналогия естественным образом вытекает из математического алгоритма. Она соответствует минимизации расстояния Кульбака-Лейблера (Kullback-Leibler divergence) между двумя распределениями (pij) и (qij):
Данная формула выражает расстояние между двумя матрицами сходства.
Чтобы минимизировать эту величину, применим градиентный спуск (gradient descent). Градиент может быть вычислен аналитически:
Здесь uij – единичный вектор, идущий от yj к yi. Этот градиент выражает сумму всех сил, приложенных к точке отображения i.
Проиллюстрируем этот процесс с помощью анимации. Необходимо реализовать «обезьяний патч» (monkey patch) для внутренней функции _gradient_descent(), которая присутствует в реализации t-SNE в библиотеке scikit-learn, чтобы иметь возможность регистрировать положение точек отображения на каждой итерации.
# This list will contain the positions of the map points at every iteration.
positions = []
def _gradient_descent(objective, p0, it, n_iter, n_iter_without_progress=30,
momentum=0.5, learning_rate=1000.0, min_gain=0.01,
min_grad_norm=1e-7, min_error_diff=1e-7, verbose=0,
args=[]):
# The documentation of this function can be found in scikit-learn's code.
p = p0.copy().ravel()
update = np.zeros_like(p)
gains = np.ones_like(p)
error = np.finfo(np.float).max
best_error = np.finfo(np.float).max
best_iter = 0
for i in range(it, n_iter):
# We save the current position.
positions.append(p.copy())
new_error, grad = objective(p, *args)
error_diff = np.abs(new_error - error)
error = new_error
grad_norm = linalg.norm(grad)
if error n_iter_without_progress:
break
if min_grad_norm >= grad_norm:
break
if min_error_diff >= error_diff:
break
inc = update * grad >= 0.0
dec = np.invert(inc)
gains[inc] += 0.05
gains[dec] *= 0.95
np.clip(gains, min_gain, np.inf)
grad *= gains
update = momentum * update - learning_rate * grad
p += update
return p, error, i
sklearn.manifold.t_sne._gradient_descent = _gradient_descent
Выполним алгоритм еще раз, но теперь сохраним все промежуточные положения.
X_proj = TSNE(random_state=RS).fit_transform(X)
X_iter = np.dstack(position.reshape(-1, 2)
for position in positions)
Создадим анимацию с помощью библиотеки MoviePy.
f, ax, sc, txts = scatter(X_iter[..., -1], y)
def make_frame_mpl(t):
i = int(t*40)
x = X_iter[..., i]
sc.set_offsets(x)
for j, txt in zip(range(10), txts):
xtext, ytext = np.median(x[y == j, :], axis=0)
txt.set_x(xtext)
txt.set_y(ytext)
return mplfig_to_npimage(f)
animation = mpy.VideoClip(make_frame_mpl,
duration=X_iter.shape[2]/40.)
animation.write_gif("https://d3ansictanv2wj.cloudfront.net/images/animation-94a2c1ff.gif", fps=20)
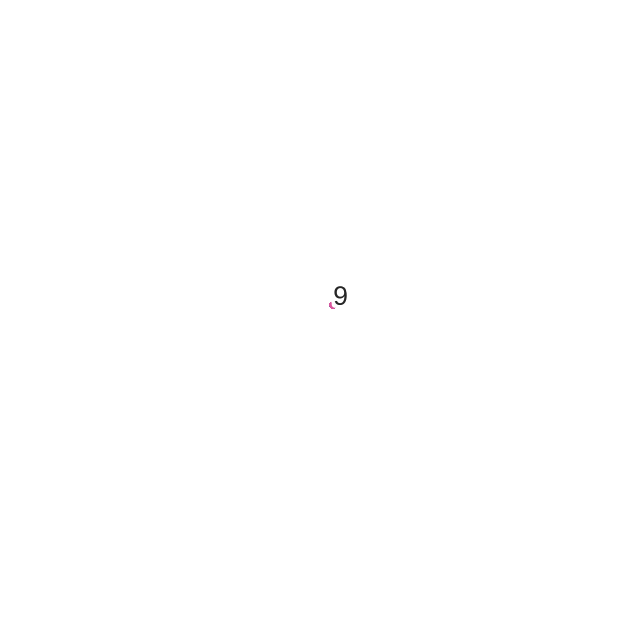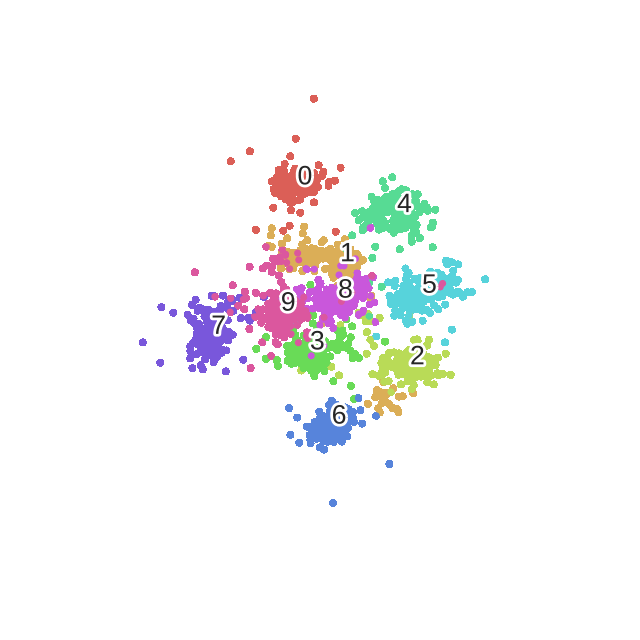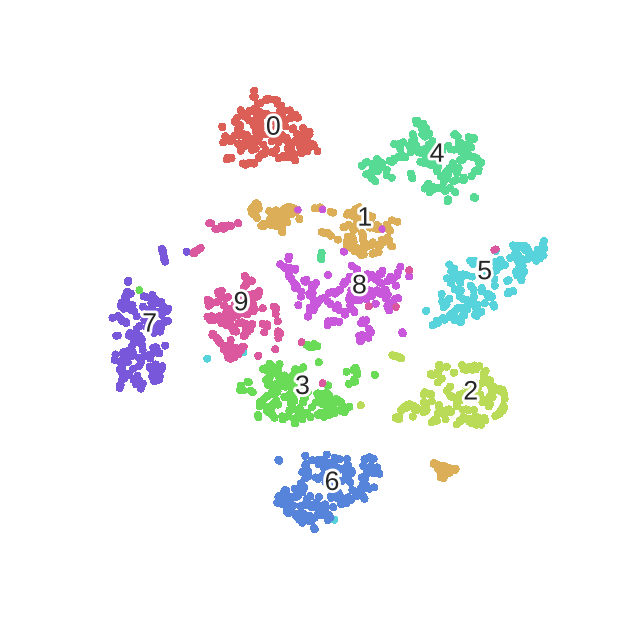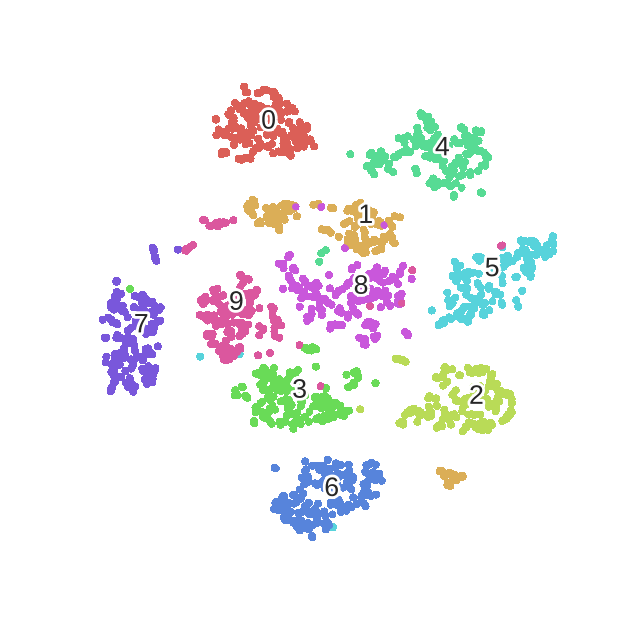
Здесь четко видны различные фазы оптимизации, как и описано в публикации.
Давайте также создадим анимацию для матрицы сходства точек отображения. Мы увидим, что она все больше и больше приближается к матрице сходства точек данных.
n = 1. / (pdist(X_iter[..., -1], "sqeuclidean") + 1)
Q = n / (2.0 * np.sum(n))
Q = squareform(Q)
f = plt.figure(figsize=(6, 6))
ax = plt.subplot(aspect='equal')
im = ax.imshow(Q, interpolation='none', cmap=pal)
plt.axis('tight')
plt.axis('off')
def make_frame_mpl(t):
i = int(t*40)
n = 1. / (pdist(X_iter[..., i], "sqeuclidean") + 1)
Q = n / (2.0 * np.sum(n))
Q = squareform(Q)
im.set_data(Q)
return mplfig_to_npimage(f)
animation = mpy.VideoClip(make_frame_mpl,
duration=X_iter.shape[2]/40.)
animation.write_gif("https://d3ansictanv2wj.cloudfront.net/images/animation_matrix-da2d5f1b.gif", fps=20)

Распределение Стьюдента
Теперь объясним, почему для точек отображения было выбрано распределение Стьюдента, в то время как для точек данных применяется нормальное распределение. Известно, что объем N-мерного шара радиуса r пропорционален rN. При больших N, если выбирать случайные точки в шаре, большинство точек будет располагаться около поверхности, и очень небольшое количество – около центра.
Моделирование, реализованное ниже, демонстрирует распределение расстояний для этих точек при различном количестве измерений.
npoints = 1000
plt.figure(figsize=(15, 4))
for i, D in enumerate((2, 5, 10)):
# Normally distributed points.
u = np.random.randn(npoints, D)
# Now on the sphere.
u /= norm(u, axis=1)[:, None]
# Uniform radius.
r = np.random.rand(npoints, 1)
# Uniformly within the ball.
points = u * r**(1./D)
# Plot.
ax = plt.subplot(1, 3, i+1)
ax.set_xlabel('Ball radius')
if i == 0:
ax.set_ylabel('Distance from origin')
ax.hist(norm(points, axis=1),
bins=np.linspace(0., 1., 50))
ax.set_title('D=%d' % D, loc='left')
plt.savefig('images/spheres-generated.png', dpi=100, bbox_inches='tight')
При уменьшении размерности набора данных, если использовать гауссово распределение для точек данных и точек отображения, мы получим дисбаланс в распределении расстояний для соседей точек. Это объясняется тем, что распределение расстояний существенно отличается для пространства большой размерности и для пространства малой размерности. Тем не менее, алгоритм пытается воспроизвести одинаковые расстояния в обоих пространствах. Этот дисбаланс создает избыток сил притяжения, что иногда приводит к неудачному отображению. Данный недостаток действительно присутствовал в первоначальном алгоритме SNE, разработанном Хинтоном и Ровейсом (Roweis) и опубликованном в 2002 году.
Алгоритм t-SNE решает эту проблему, используя распределение Стьюдента с одной степенью свободы (или распределение Коши) для точек отображения. В отличие от гауссова распределения, это распределение имеет значительно более «тяжелый» хвост, что позволяет компенсировать дисбаланс. Для данного сходства между двумя точками данных, две соответствующие точки отображения должны находиться намного дальше друг от друга, чтобы их сходство соответствовало сходству точек данных. Это можно увидеть на следующем графике.
z = np.linspace(0., 5., 1000)
gauss = np.exp(-z**2)
cauchy = 1/(1+z**2)
plt.plot(z, gauss, label='Gaussian distribution')
plt.plot(z, cauchy, label='Cauchy distribution')
plt.legend()
plt.savefig('images/distributions-generated.png', dpi=100)
Использование этого распределения обеспечивает более эффективную визуализацию данных, при которой группы точек более отчетливо отделены друг от друга.
Заключение
Алгоритм t-SNE обеспечивает эффективный метод визуализации сложных наборов данных. Он успешно обнаруживает скрытые структуры в данных, демонстрирует группы и компенсирует нелинейные отклонения по измерениям. Данный алгоритм реализован на многих языках программирования, в том числе на Python, и может быть легко применен благодаря библиотеке scikit-learn.
По материалам: O’Reilly